Meta推出类“ChatGPT”语言模型LLaMA:最高650亿参数,免费面向研究人员
添加书签

2月25日,Facebook母公司Meta发布了大语言模型LLaMA。这是目前最先进的语言模型,现阶段免费面向研究人员,以帮助他们加速生成式AI研发进程。(试用申请地址:https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform)
据悉,LLaMA模型与ChatGPT同样是基于Transformers模型演变而来。LLaMA共有70亿、130亿、330亿和650亿参数四种类型,接受了20种不同语言文本的训练,这使得研究人员能以更少的计算能力和资源来测试新的方法和探索新的用例。(发送“LLaMA论文”消息,获取原版论文。)
扎克伯格在社交平台表示,LLaMA在生成文本、进行对话、总结书面材料以及解决数学定理或预测蛋白质结构等,更复杂的任务方面表现出了很大的潜力。会将新的模型提供给AI研究人员和机构。
目前,LLaMA没有任何商业用途计划不为用户提供服务,只免费提供给AI研究人员和机构用于科研使用。
ChatGPT的出现使得微软、谷歌等科技巨头拉开了新一轮“AI军备赛”。在过去一段时间,ChatGPT在全球疯狂刷屏成为一款现象级智能产品,仅用2个月的时间月活便突破1亿大关,成为史上增速最快的消费级应用。
但对于其他玩家或AI研究机构来说只能“干瞪眼”,无法获取相匹配的技术、资源参与到这场战斗中。因此,Meta并没有急于推出面向用户的商用版“ChatGPT”,而是瞄准了处于荒漠的开源领域。(LLaMA在Github上简版地址:https://github.com/facebookresearch/llama)。
据Meta介绍,在数据训练方面,LLaMA使用公开可用的数据集进行训练,其中包括开放数据平台Common Crawl、英文文档数据集C4、代码平台GitHub、维基百科、论文预印本平台ArXiv等,总体标记数据总量大约在1.4万亿个Tokens左右。

Meta认为,在更多标记(单词)上训练的较小模型,更容易针对特定的潜在产品用例进行再训练和微调。例如,LLaMA在1.4万亿个Tokens上训练了330亿和650亿参数;在1万亿个Tokens上训练了70亿参数。
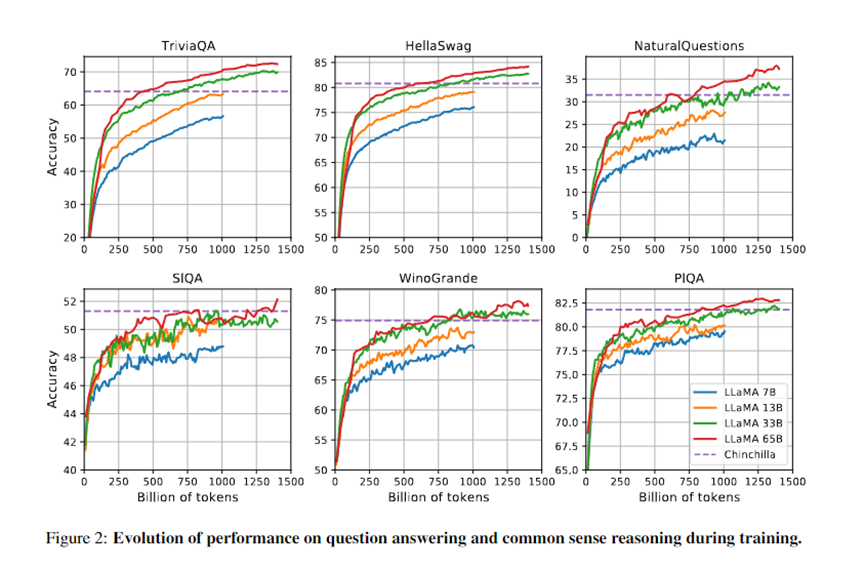
内容生成方面,LLaMA与其他大语言模型一样,是将一系列单词作为输入并预测下一个单词以递归生成文本。为了扩大文本边界,LLaMA使用了20多种语言文本进行训练。
LLaMA开源的另外一个重要目的就是解决产品的偏见、恶意评论和虚假信息等。据英国《自然》杂志报道,有科研人员发现,由大语言模型(LLM)支持的ChatGPT,主要通过学习庞大的网络文本数据库,例如,网络文本、维基百科、文章、论坛等来自动生成内容。

其中就包括了不真实、偏见、歧视或过时的知识,因此,很容易产生错误和误导性的信息,造成更严重的社会问题。例如,国外一位用户曾问ChatGPT关于CEO的问题,而它只回答了与白人相关的内容,这就引发了种族的社会问题。
所以,LLaMA希望通过开源的方式借助全球科研机构的力量,尽可能地消除大语言模型中所存在的诸多负面内容完善产品功能。
总体来说,随着ChatGPT的热度持续“狂飙”,“AI军备赛”将越发激烈,吸引更多的科技巨头参与到这场竞技中。ChatGPT作为AIGC文本领域的王牌产品,也将进一步推动AIGC的市场增长。据东吴证券预计,AIGC在内容生成市场的渗透率将快速上升,预计到2030年AIGC市场规模将超过万亿元。
END
加入AIGC开放社区交流群
添加微信:13331022201 ,备注“职位信息&名字”,在管理员审核后加入讨论群



