大模型综述升级啦!
添加书签
专注AIGC领域的专业社区,关注OpenAI、百度文心一言等大语言模型(LLM)的发展和应用落地,关注LLM的基准评测和市场研究,欢迎关注!

-
新增了对LLaMA模型及其衍生模型组成的LLaMA家族介绍; -
新增了具体实验分析,包括指令微调数据集组合方式实验以及部分模型综合能力评测; -
新增了大语言模型提示设计提示指南以及相关实验,总结了提示设计的原则、经验; -
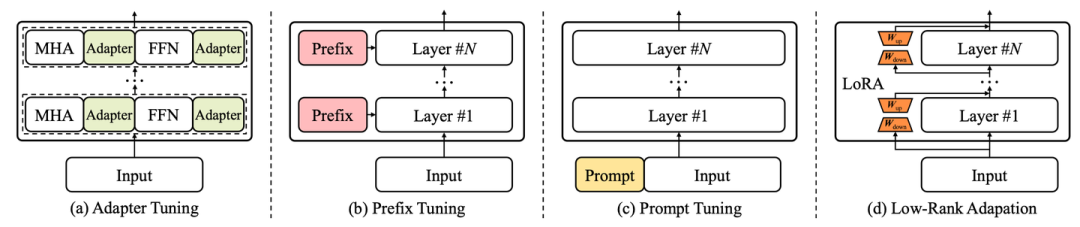
新增了参数高效适配和空间高效适配章节,总结了大语言模型相关的轻量化技术; -
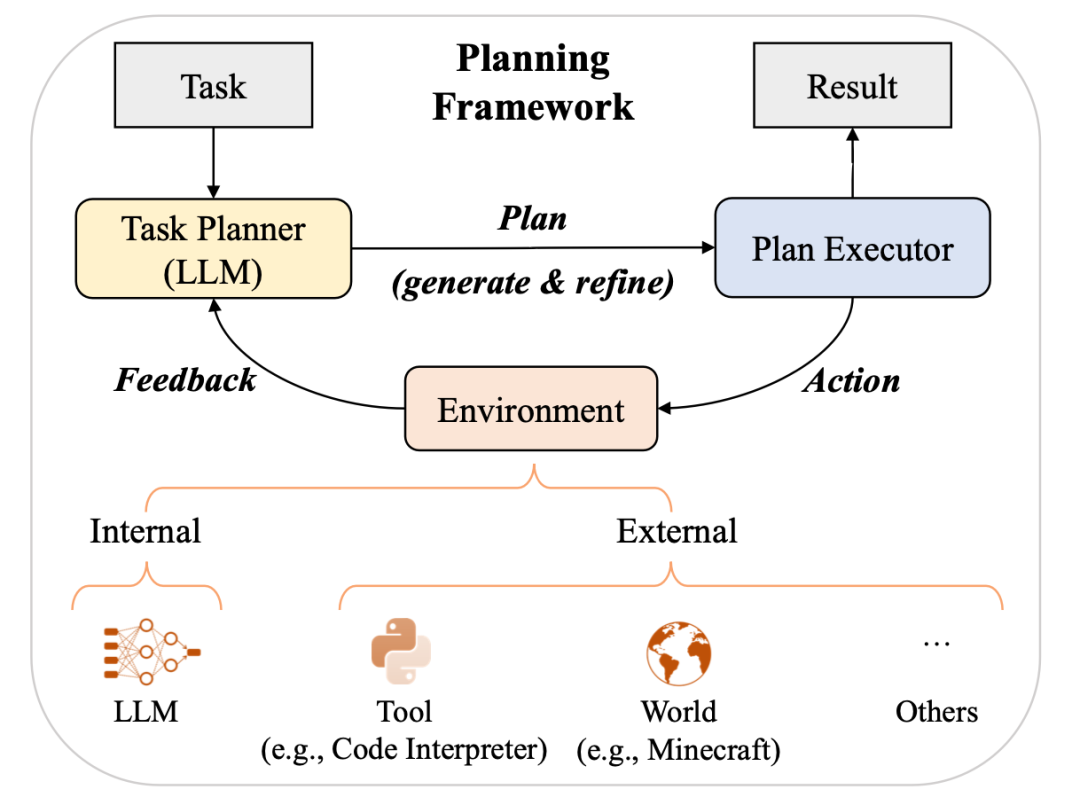
增加了对于规划(planning)的相关工作介绍; -
增补了许多脉络梳理内容,以及大量最新工作介绍;

-
论文链接:https://arxiv.org/abs/2303.18223 -
GitHub项目链接:https://github.com/RUCAIBox/LLMSurvey -
中文翻译版本链接:https://github.com/RUCAIBox/LLMSurvey/blob/main/assets/LLM_Survey__Chinese_V1.pdf
1. 引言
2. 总览
-
KM 扩展法则
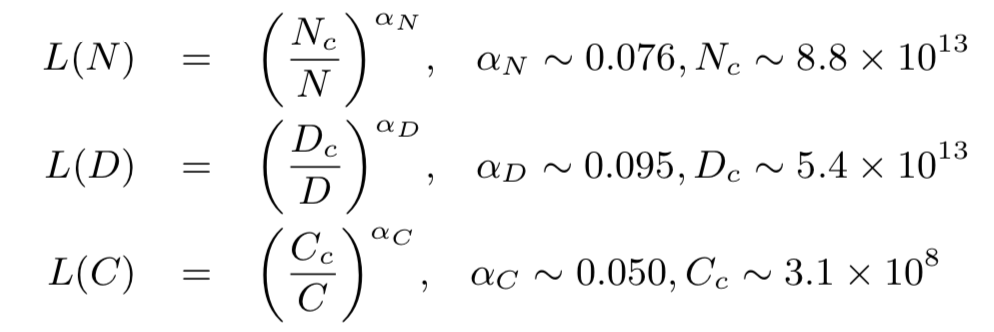
-
Chinchilla扩展法则
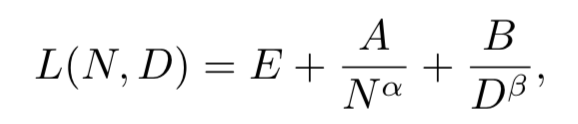
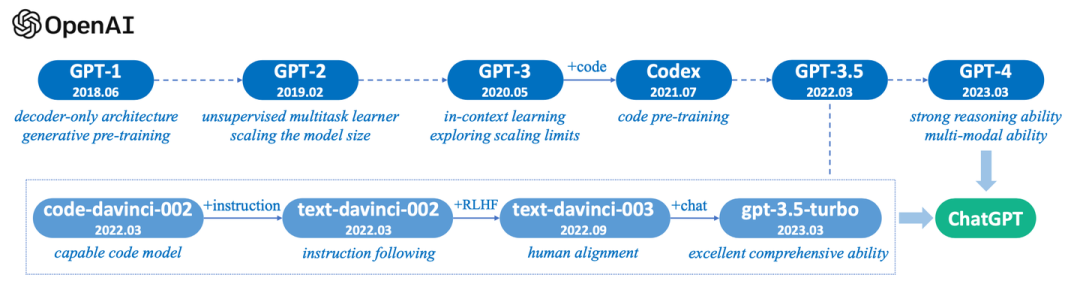

3. 大语言模型相关资源
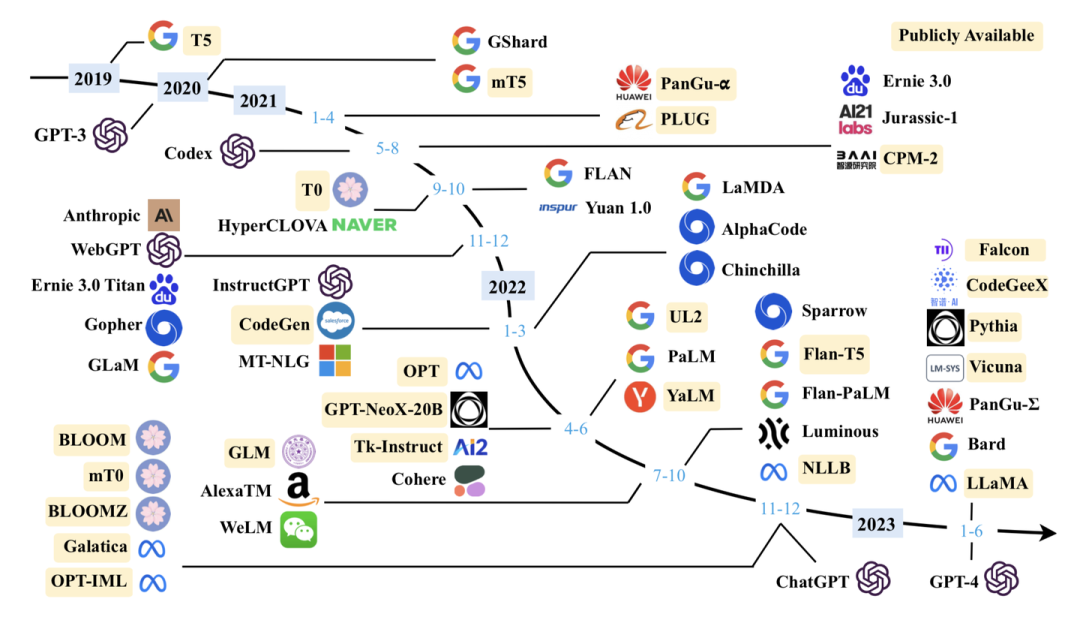

4. 大语言模型预训练技术
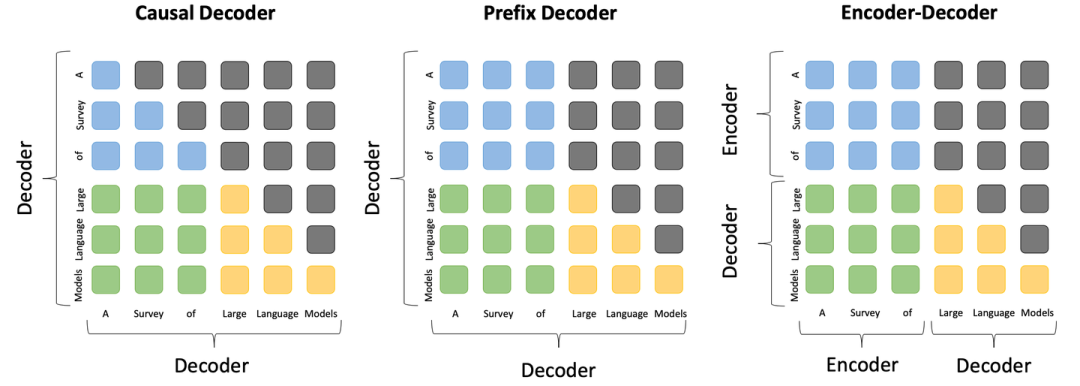


5. 大语言模型适配技术
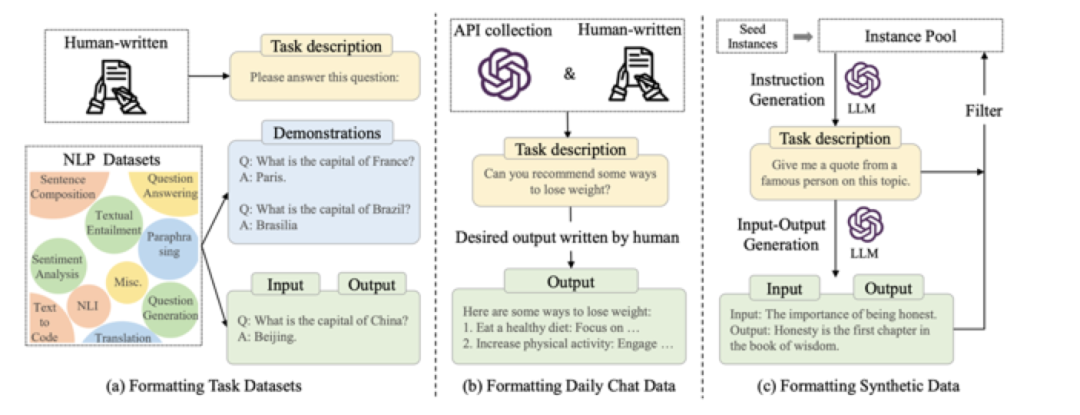
在适配技术章节,我们扩充了指令微调的技术细节,包括指令收集方法、指令微调的作用、指令微调的结果和对应分析。首先,我们按照任务指令、聊天指令、合成指令三类分别介绍了指令数据的收集方法,并收集了的指令集合。
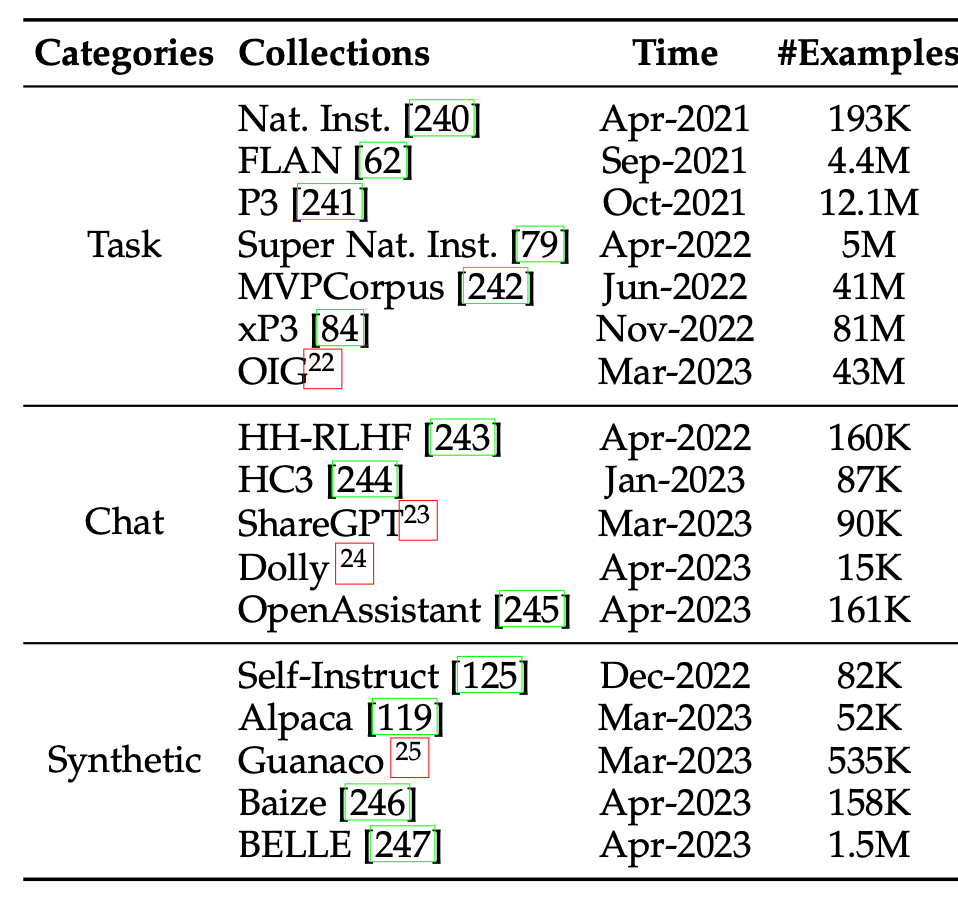
并且更新了指令集合的创建方式示意图:


6. 大语言模型使用技术
7. 大语言模型能力评估


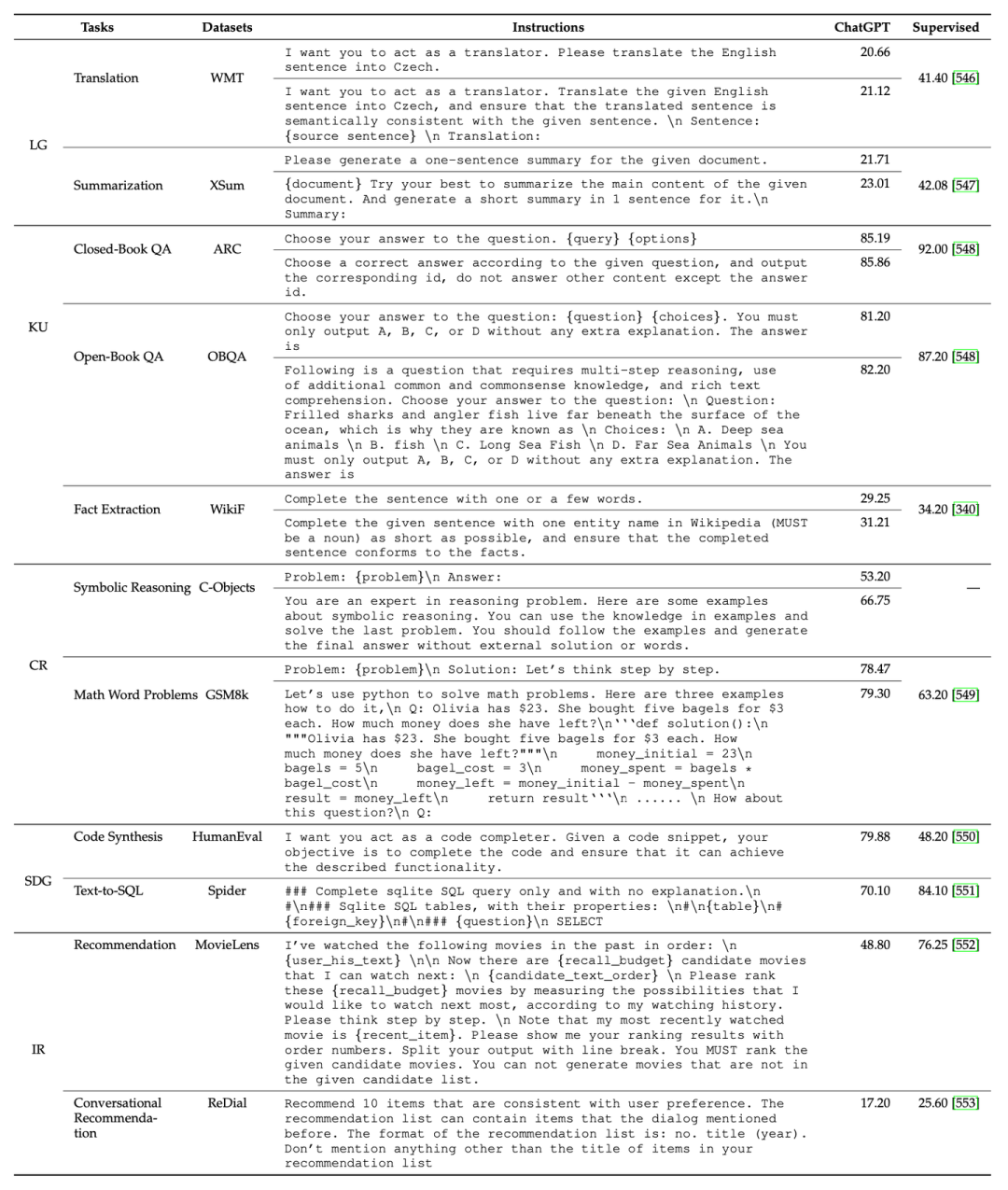
8. 大语言模型提示设计使用指南

增加了相关提示的示意图:

9. 大语言模型领域应用
10. 寻求建议与算力
11. 本次修订的参与学生名单
附件:更新日志
| 版本 | 时间 | 主要更新内容 |
|---|---|---|
| V1 | 2023年3月31日 | 初始版本 |
| V2 | 2023年4月9日 | 添加了机构信息。修订了图表 1 和表格 1,并澄清了大语言模型的相应选择标准。改进了写作。纠正了一些小错误。 |
| V3 | 2023年4月11日 | 修正了关于库资源的错误 |
| V4 | 2023年4月12日 | 修订了图1 和表格 1,并澄清了一些大语言模型的发布日期 |
| V5 | 2023年4月16日 | 添加了关于 GPT 系列模型技术发展的章节 |
| V6 | 2023年4月24日 | 在表格 1 和图表 1 中添加了一些新模型。添加了关于扩展法则的讨论。为涌现能力的模型尺寸添加了一些解释(第 2.1 节)。在图 4 中添加了用于不同架构的注意力模式的插图。在表格 4 中添加了详细的公式。 |
| V7 | 2023年4月25日 | 修正了图表和表格中的一些拷贝错误 |
| V8 | 2023年4月27日 | 在第 5.3 节中添加了参数高效适配章节 |
| V9 | 2023年4月28日 | 修订了第 5.3 节 |
| V10 | 2023年5 月7 日 | 修订了表格 1、表格 2 和一些细节 |
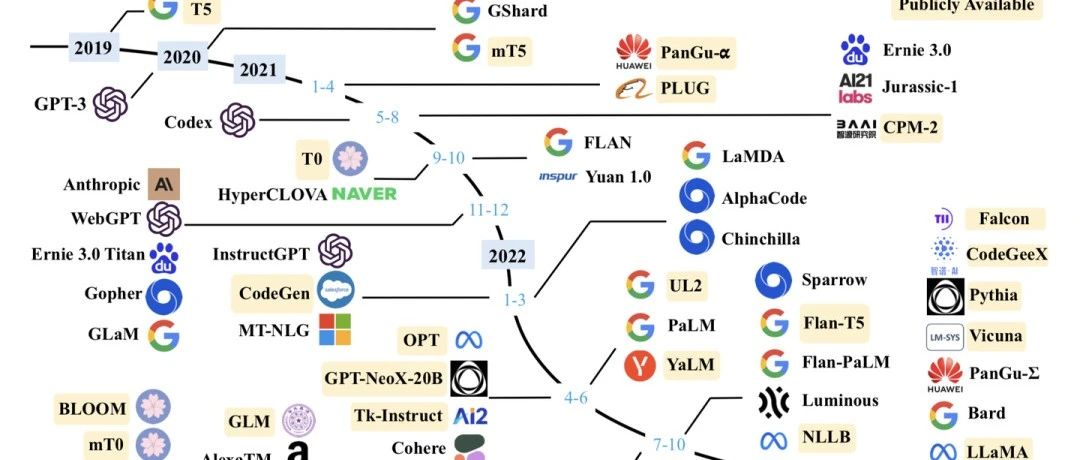
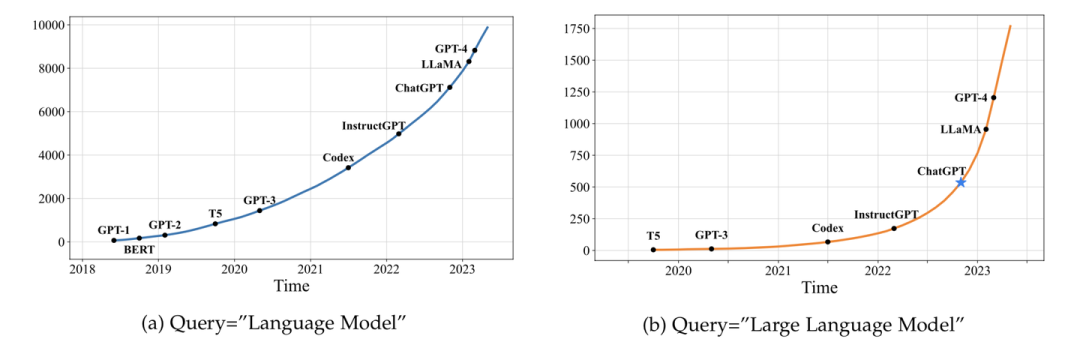
| V11 | 2023年6月29日 | 第一章:添加了图1,在arXiv上发布的大语言论文趋势图;第二章:添加图3以展示GPT的演变及相应的讨论;第三章:添加图4以展示LLaMA家族及相应的讨论;第五章:在5.1.1节中添加有关指令调整合成数据方式的最新讨论, 在5.1.4节中添加有关指令调整的经验分析, 在5.3节中添加有关参数高效适配的讨论, 在5.4节中添加有关空间高效适配的讨论;第六章:在6.1.3节中添加有关ICL的底层机制的最新讨论,在6.3节中添加有关复杂任务解决规划的讨论;第七章:在7.2节中添加用于评估LLM高级能力的代表性数据集的表格10,在7.3.2节中添加大语言模型综合能力pint测;第八章:添加提示设计;第九章:添加关于大语言模型在金融和科学研究领域应用的讨论。 |
本文素材来源xxxx,如有侵权请联系删除
END




