文本自动生成6种语音,Meta推出多任务语音模型——Voicebox
添加书签

专注AIGC领域的专业社区,关注OpenAI、百度文心一言等大语言模型(LLM)的发展和应用落地,关注LLM的基准评测和市场研究,欢迎关注!
近日,Meta(Facebook、Instagram等母公司)推出了可执行多种任务的生成式语音模型——Voicebox。(论文地址:https://research.facebook.com/publications/voicebox-text-guided-multilingual-universal-speech-generation-at-scale/)
Voicebox支持文本自动生成英语、法语、德语、西班牙语、波兰语或葡萄牙语6种语音,还提供去除噪声、语音编辑、风格转换和多样化语音合成功能。总之,这是一个开创性语音模型,属于语音模型界的“ChatGPT”。
Voicebox的主要用途:帮助媒体人轻松编辑音轨,例如,录音时背景出现狗叫的声音,通过Voicebox轻松去除;语音克隆 ,即便无法说话的人“啊~啊”两声,Voicebox仅需2秒钟就能克隆其声音,应用在文本转语音功能;
Voicebox可生成6种自然语言的语音,所以,该功能可用于生成语音训练数据,帮助企业、个人开发者更好的训练语音助手模型。

目前,Meta在大语言、扩散、视觉切割、语音等领域,发布了很多功能强大的模型,例如,其开源的LLaMA已成为类ChatGPT开源模型中应用最多、影响力最大的模型之一。
前不久在Meta的高层会议上,扎克伯格表示,未来Meta的Instagram、Whatsapp、Messenger等招牌产品都会引入生成式AI功能,为用户提供文本生成、图片生成、AI聊天等服务,加大对生成式AI的布局赶上微软、谷歌的脚步。
Voicebox介绍
Voicebox突破技术限制,使用全新方法
多数传统的语音合成器需要使用单一、干净的音乐数据用于训练,这就有两个很大的局限性。第一,干净的音乐数据获取较难,并且数量有限;第二,由于训练数据有限,所以输出的语音模型过于单调枯燥。
为了突破这些技术限制,Voicebox是基于Flow Matching模型(论文地址:https://arxiv.org/abs/2210.02747)构建而成,可以学习文本和语音之间高度不确定的映射联系。
不确定性映射很有用,使得Voicebox 能够从不同的语音数据中学习,而无需仔细标记这些变化。也就是说,Voicebox 可以在更大规模的数据集上进行训练。
Voicebox使用超过5万小时的语音录音和来自英语、法语、西班牙语、德语、波兰语和葡萄牙语,公共领域有声读物的转录音频来训练 Voicebox。

Voicebox可以在给定周围语音和片段的转录本时,预测语音片段。在学会从上下文中填充语音后就能用于多种语音生成任务,例如,在录音中间生成缺失部分,使得用户无需重新创建整个输入。
Voicebox功能介绍
文本到语音合成:用户使用长度仅为2秒的输入音频样本,Voicebox 就可以自动匹配样本的音频风格并将其用于文本到语音生成。该功能可以帮助很多无法说话的聋哑人,实现“说话”。
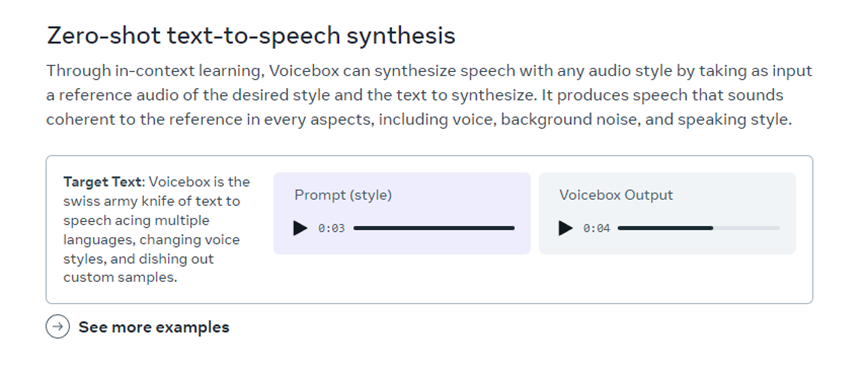
跨语言风格生成:给定一个语音样本和一段英语、法语、德语、西班牙语、波兰语或葡萄牙语的文本,Voicebox 都能以该语言读出该文本。该功能可以帮助人们用自己的语音进行真实地交流,即便他们来自不同的国家、地区。
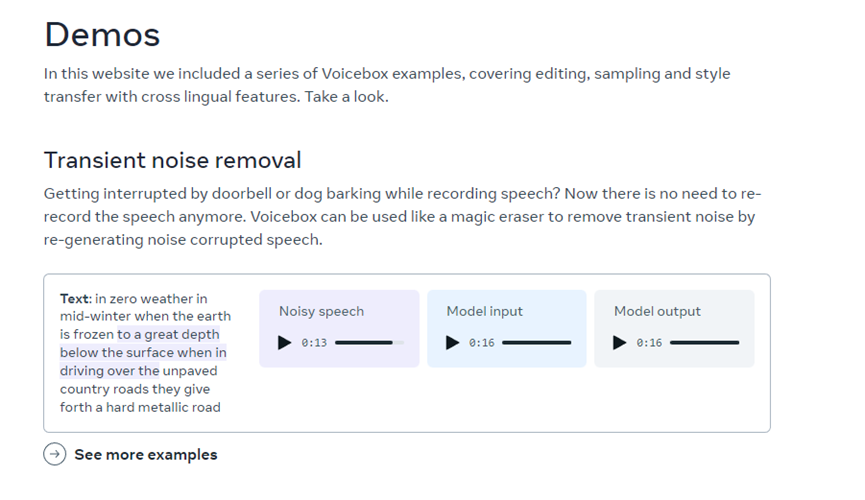
语音降噪和编辑:Voicebox 的上下文学习能力,可以在音频录音中生成无缝衔接的语音片段。例如,可以用于被噪声破坏的语音、纠正说错的文本等。所以,该功能可以帮助专业媒体人更快的编辑音频。
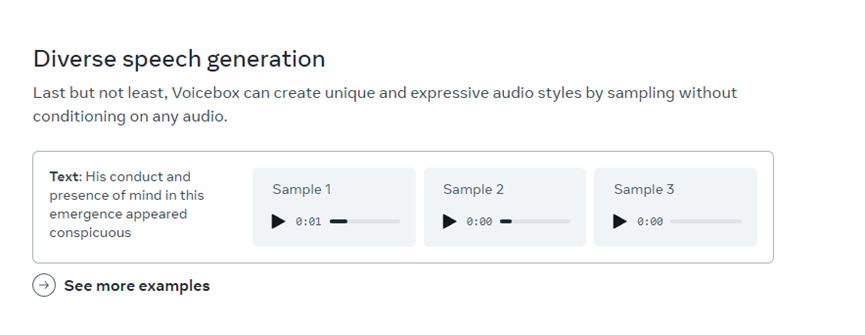
多样化语音采样:从多样化的自然数据中学习后,Voicebox 可以生成贴近现实说话的声音,并且支持英语、法语、德语、西班牙语、波兰语和葡萄牙语六种语言。所以,可用于生成语音数据,可帮助用户更好地训练语音助手模型。
Meta表示,由于语音模型存在滥用的风险,会被非法人员用于电信诈骗等,所以,目前不会分享Voicebox模型和代码。但已经开放了Voicebox的论文,并且介绍了Meta如何构建一个高效的分类器,该分类器可以区分使用 Voicebox 生成的真实语音和音频。
本文素材来源Meta官网,如有侵权请联系删除
END




