专注AIGC领域的专业社区,关注OpenAI、百度文心一言等大语言模型(LLM)的发展和应用落地,关注LLM的基准评测和市场研究,欢迎关注!
近日,搜狗创始人王小川创立的百川智能公司,宣布开源了70亿参数的大规模预训练语言模型——baichuan-7B。
baichuan-7B基于Transformer 结构,支持中英双语、可商用,上下文窗口长度为4096,在大约1.2万亿 tokens上进行了训练。
开源地址:https://github.com/baichuan-inc/baichuan-7B
Hugging Face:https://huggingface.co/baichuan-inc/baichuan-7B
baichuan-7B在三个最具影响力的中文评估基准中,在同等参数量级大模型中的综合评分十分亮眼:
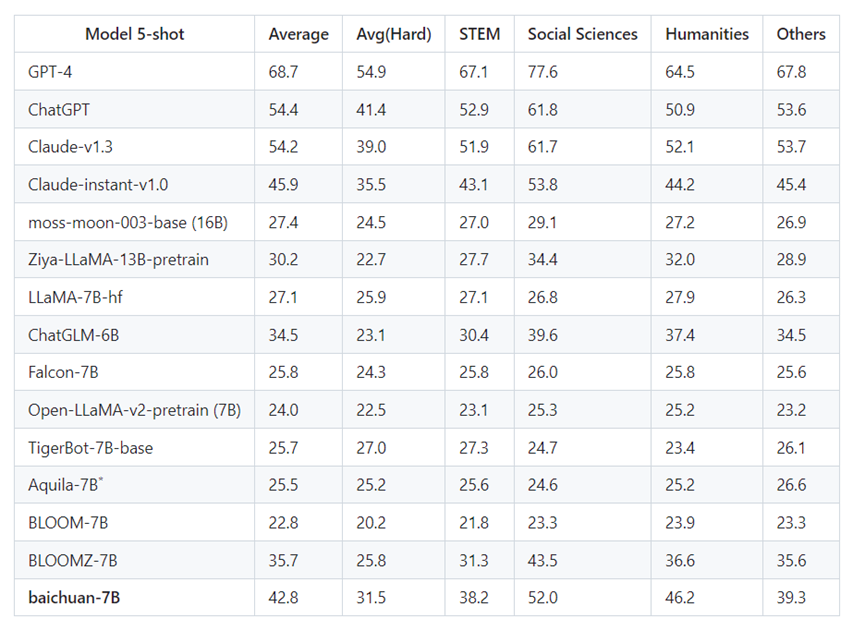
微软研究院发起的评测标准 AGI Eval中,baichua -7B 综合评分34.4,在中国高考、司法考试、SAT、LSAT、GRE 等考试中发挥很好,领先于LLaMa-7B、Falcon-7B、Bloom-7B 以及 ChatGLM-6B 等不少竞争对手;
C-Eval——由上交、清华、爱丁堡大学三个顶级院校联合创建的评测标准中,baichuan-7B 发挥同样出色。在覆盖了52个学科的测评中,baichuan-7B 获评34.4分,在同量级产品中排名第一。
在跑分中,baichuan-7B 的表现甚至比起一些参数量级更大的模型更优秀,其中有些参数甚至是baichuan-7B 的四倍以上。榜单上,比起130亿参数的GLM-130B 一个月前的测试结果, baichuan-7B 的综合评分也仅相差1.2分。
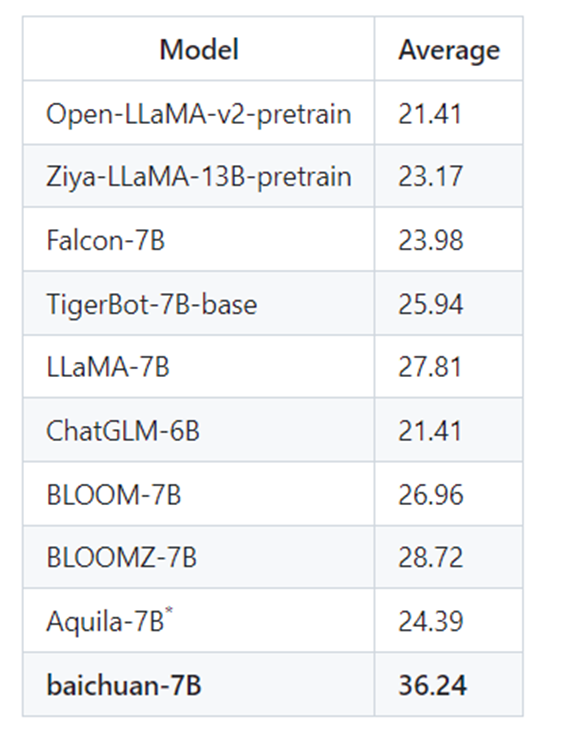
在复旦大学研究团队所创建的 GAOKAO 评测框架中,baichuan-7B 在高考题目上的表现同样惊艳,不仅评分在同参数量级的模型中拔得头筹,并且领先第二名近8分。
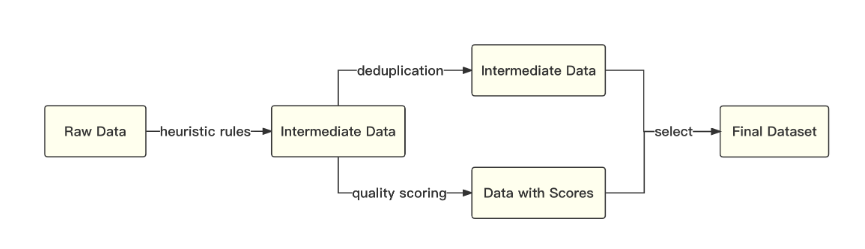
baichuan-7B原始数据包括开源的中英文数据和自行抓取的中文互联网数据,以及部分高质量知识性数据。参考相关数据工作,频率和质量是数据处理环节重点考虑的两个维度。
百川智能基于启发式规则和质量模型打分,对原始数据集进行篇章和句子粒度的过滤。在全量数据上,利用局部敏感哈希方法,对篇章和句子粒度做滤重。
经过不断的调整和多轮测试,最终确认了一个在下游任务上表现最好的中英文配比。百川智能使用了一个基于自动学习的数据权重策略,对不同类别的数据进行配比。
百川智能参考学术界方案使用 SentencePiece 中的 byte pair encoding (BPE)作为分词算法,并且进行了以下的优化:
1)目前大部分开源模型主要基于英文优化,因此对中文语料存在效率较低的问题。百川智能使用2000万条以中英为主的多语言语料训练分词模型,显著提升对于中文的压缩率。
2)对于数学领域,百川智能参考了 LLaMA 和 Galactica 中的方案,对数字的每一位单独分开,避免出现数字不一致的问题,对于提升数学能力有重要帮助。
3)对于罕见字词(如特殊符号等),支持UTF-8-characters 的 byte 编码,因此做到未知字词的全覆盖。
4)百川智能分析了不同分词器对语料的压缩率,可见百川智能的分词器明显优于 LLaMA, Falcon 等开源模型,并且对比其他中文分词器在压缩率相当的情况下,训练和推理效率更高。
baichuan-7B基于标准的 Transformer 结构,百川智能采用了和 LLaMA 一样的模型设计。
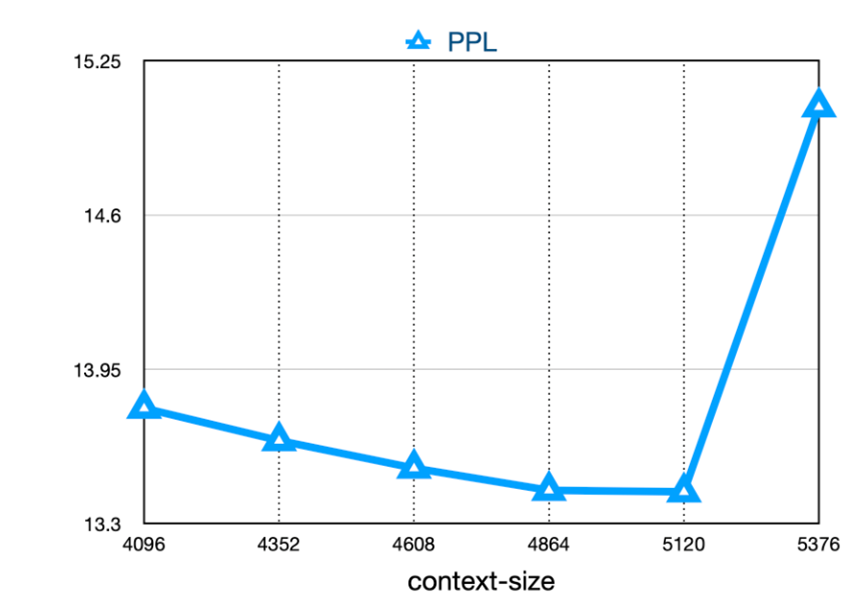
位置编码:rotary-embedding是现阶段被大多模型采用的位置编码方案,具有更好的外延效果。虽然训练过程中最大长度为4096,但是实际测试中模型可以很好的扩展到 5000 tokens。
激活层:SwiGLU, Feedforward 变化为(8/3)倍的隐含层大小,即11008。
Layer-Normalization:基于 RMSNorm 的 Pre-Normalization。
本文素材来源百川智能,如有侵权请联系删除
END