谷歌PaLM 2细节曝光:3.6万亿token,3400亿参数
添加书签

专注AIGC领域的专业社区,关注GPT-4、百度文心一言、华为盘古等大语言模型(LLM)的发展和应用落地,以及国内LLM的发展和市场研究,欢迎关注!
金磊 发自 凹非寺
量子位 | 公众号 QbitAI
谷歌最新大语言模型PaLM 2,更细节内幕被曝出来了!
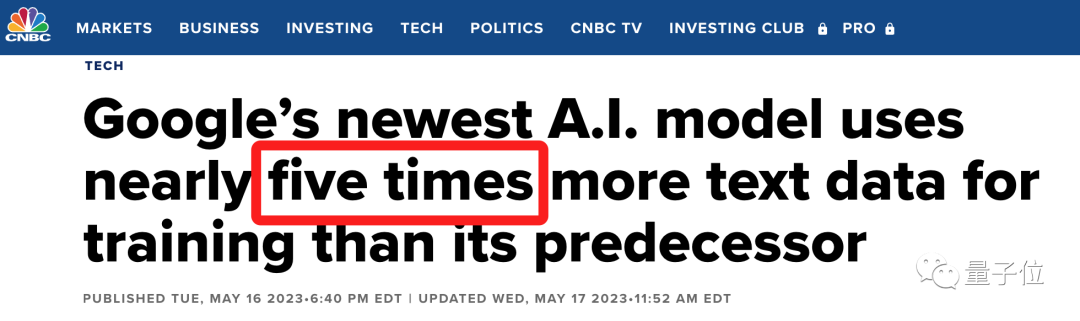
据CNBC爆料,训练它所用到的token数量多达3.6万亿。

这是什么概念?
要知道,在去年谷歌发布PaLM时,训练token的数量也仅为7800亿。
四舍五入算下来,PaLM 2足足是它前身的近5倍!
(token本质是字符串,是训练大语言模型的关键,可以教会模型预测序列中出现的下一个单词。)
不仅如此,当时谷歌发布PaLM 2时,只是提到“新模型比以前的LLM更小”。
而内部文件则是将具体数值爆料了出来——3400亿个参数(初代PaLM是5400亿)。
这表明,谷歌通过技术“buff加持”,在参数量更小的情况下,让模型可以更高效地完成更复杂的任务。
虽然在已经维持了数月的AIGC大战中,谷歌一直“全军出击”,但对于训练数据的大小或其他细节信息,却是遮遮掩掩的态度。
而随着这次内部文档的曝光,也让我们对谷歌最in大语言模型有了进一步的了解。
PaLM 2要在广告上发力了
关于谷歌上周发布PaLM 2的能力,我们就不再详细的赘述(可点击此处了解详情),简单总结下来就是:
-
接受了100多种语言的训练,在语言理解、生成和翻译上的能力更强,更加擅长常识推理、数学逻辑分析。
-
数据集中有海量论文和网页,其中包含非常多数学表达式。
-
支持20种编程语言,如Python、JavaScript等常用语言。
-
推出了四种不同size:“壁虎”版、“水獭”版、“野牛”版和“独角兽”版(规模依次增大)。

至于使用方面,谷歌在发布会中就已经介绍说有超过25个产品和应用接入了PaLM 2的能力。
具体表现形式是Duet AI,可以理解为对标微软365 Copilot的一款产品;在现场也展示了在Gmail、Google Docs、Google Sheets中应用的能力。
而现在,CNBC从谷歌内部文件中挖出了其在PaLM 2应用的更多计划——进军广告界。
根据这份内部文件,谷歌内部的某些团队现在计划使用PaLM 2驱动的工具,允许广告商生成自己的媒体资产,并为YouTube创作者推荐视频。
谷歌也一直在为YouTube的青少年内容测试PaLM 2,比如标题和描述。

谷歌在经历了近20年的快速发展后,现在已然陷入了多季度收入增长缓慢的“泥潭”。
也由于全球经济大环境等原因,广告商们也一直在在线营销预算中挣扎。
具体到谷歌,今年大多数行业的付费搜索广告转化率都有所下降。
而这份内部文件所透露出来的信号,便是谷歌希望抓住AIGC这根救命稻草,希望使用生成式AI产品来增加支出,用来增加收入并提高利润率。
据文件显示,AI驱动的客户支持策略可能会在100多种谷歌产品上运行,包括Google Play商店、Gmail、Android搜索和地图等。
训练数据缺乏透明度,越发被热议
不过话说回来,包括谷歌在内,纵观大多数大语言模型玩家,一个较为明显的现象就是:
对模型、数据等细节保密。
这也是CNBC直接挑明的一个观点。

虽然很多公司都表示,这是因为业务竞争所导致的,但研究界却不这么认为。
在他们看来,随着AIGC大战的持续升温,模型、数据等需要更高的透明度。
而与之相关的话题热度也是越发的激烈。
例如谷歌Research高级科学家El Mahdi El Mhamdi便于二月份辞职,此举背后的原因,正是因为他觉得公司缺乏透明度。
无独有偶,就在OpenAI CEO Sam Altman参与听证会期间,便“反向”主动提出立法者进行监管:
如果这项技术出了问题,那就可能会是大问题……我们希望合作,防止这种情况发生。

截至发稿,对于CNBC所爆料的诸多内容,谷歌方面暂未做出回应。
参考链接:
[1]https://www.cnbc.com/2023/05/16/googles-palm-2-uses-nearly-five-times-more-text-data-than-predecessor.html
[2]https://www.cnbc.com/2023/05/17/google-to-use-new-ai-models-for-ads-and-to-help-youtube-creators.html
[3]https://ai.google/discover/palm2
本文来源量子位,如有侵权请联系删除
END
「AIGC开放社区」ChatGPT对话机器人大合集,扫描二维码免费使用