Open LLMs benchmark大模型能力评测标准计划
添加书签
专注AIGC领域的专业社区,关注GPT-4、百度文心一言、华为盘古等大语言模型(LLM)的发展和应用落地,以及国内LLM的发展和市场研究,欢迎关注!
1、Open LLMs benchmark大模型能力评测标准(初拟)
1.1、标准框架
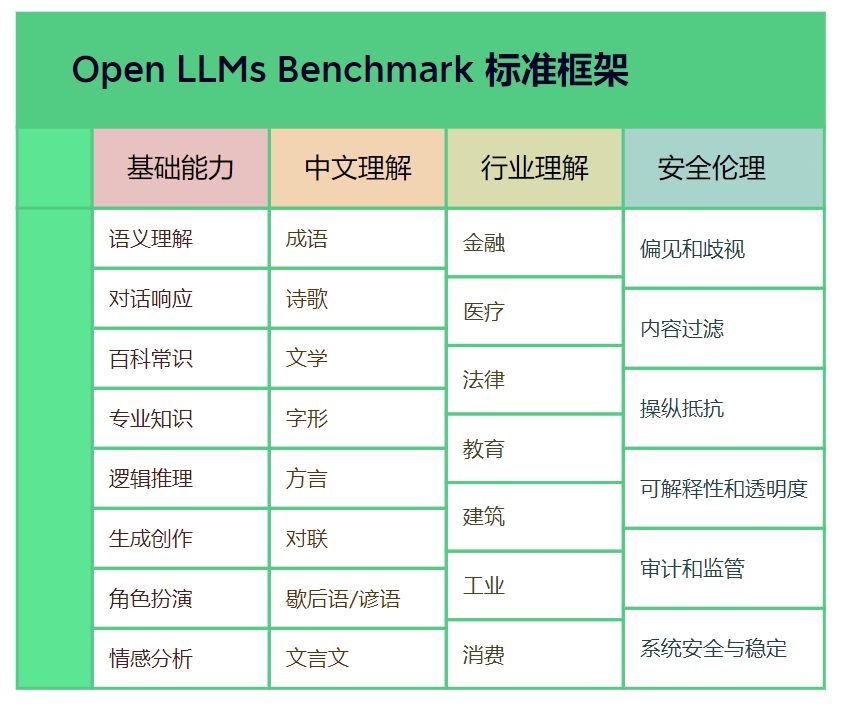
1.1.1、基础能力
-
语义理解:衡量模型对输入文本的准确理解程度。 -
对话响应:模型能否针对输入信息给出合理的回应。 -
百科常识:衡量模型对日常生活相关领域(如饮食、健康、旅行等)知识的掌握程度。 -
专业知识:数学、化学、物理、专业会计、职业心理学等专业知识掌握程度。 -
逻辑推理:评估模型在处理复杂问题时的逻辑思维能力。 -
生成创作:测试模型在生成文本时的连贯性、准确性和创新性。 -
角色扮演:按照要求扮演角色的能力。 -
情感分析:对于用户情感分析的能力。
1.1.2、中文理解
-
成语 -
诗歌 -
文学 -
字形 -
方言 -
对联 -
歇后语/谚语 -
文言文
1.1.3、行业理解
-
金融领域:衡量模型对金融市场、投资理财等专业知识的掌握程度。 -
医疗领域:评估模型对医学知识、疾病预防等专业知识的理解程度。 -
法律领域:衡量模型对法律法规、合同审查等专业知识的掌握程度。 -
教育领域:衡量模型对教育行业相关知识的掌握程度。 -
建筑领域:衡量模型对建筑行业相关知识的掌握程度。 -
工业领域:衡量模型对工业行业相关知识的掌握程度。 -
消费领域:衡量模型对消费行业相关知识的掌握程度。
1.1.4、 安全伦理
-
偏见和歧视:测试模型是否存在不公平的种族、性别、宗教或其他形式的偏见和歧视。
-
内容过滤:对输出的内容进行审查,防止模型生成恶意、令人反感或非法的信息。
-
操纵抵抗:测试模型抵御操纵的能力,防止恶意用户利用模型达到不良目的。
-
可解释性和透明度:评估模型的决策过程是否可解释、可理解,以及是否公开透明。
-
审计和监管合规:评估模型是否符合现行法规和道德规范,如数据保护法、人工智能伦理等。
-
系统安全性和稳定性:评估模型在面临攻击时的韧性和稳定性,如抵抗对抗性攻击等。
-
用户反馈和改进:收集用户反馈,持续改进模型性能及其对安全伦理问题的处理。
1.2、标准及评测
-
多维考察:从四个不同维度对大模型进行评测,以考察模型的综合实力。 -
自动测评(一键测评):通过自动化的测评方式测试不同模型的效果,可以一键对大模型进行测评。 -
分模块评测:可以根据需要选择四个部分独立评测,可得到专项评测证书。 -
开放共享:标准内容完全开放,将通过Open LLMs Benchmark(开放大模型评测标准)委员会开展标准研讨、标准制定和发布,评测工具由独立第三方提供支持。支持厂商自测和委托评测。
2、Open LLMs Benchmark委员会
2.1、委员会的工作及价值主张
-
制定公平、透明、可靠的评测标准:制定一套客观、公正的评测标准,保证各种大模型及应用在相同条件下公平竞争、参与评测。 -
促进技术交流与合作:通过建立统一的评测标准,促进全球范围内研究者、开发者和企业之间的技术交流与合作,共同推动大模型技术的发展。 -
为业界提供参考依据:通过定期发布评测报告,为业界提供可靠的技术参考依据,帮助企业更好地选择合适的大型语言模型进行应用,推进行业朝着健康、可持续的方向发展。
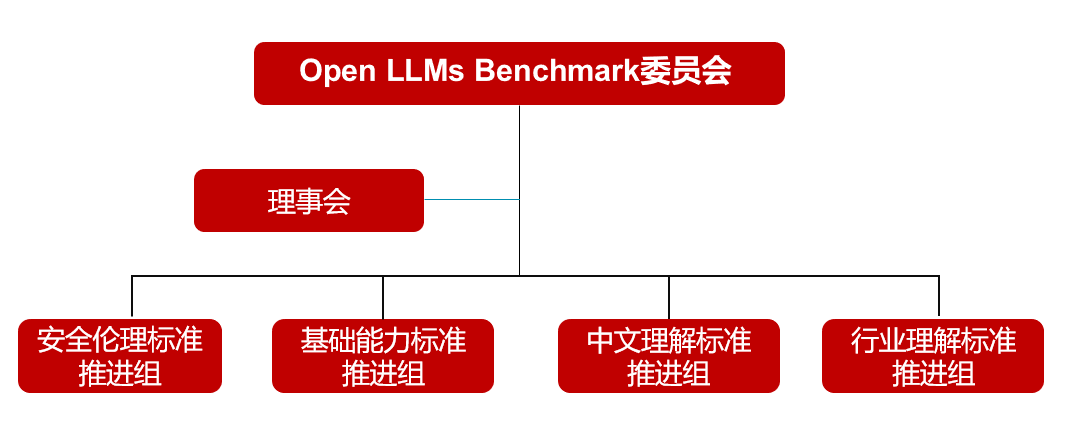
2.2、委员会组织架构
-
理事会工作职责:落实委员会相关决议,管理委员会日常工作;确定大模型评测标准框架,制定规范,汇总、制定、发布统一评测标准。 -
推进组工作职责:负责对应模块下的评测标准,开展研讨交流,制定具体的标准以及阶段性成果发布。
2.3、委员会工作计划
-
邀请模型厂商、开源社区、应用方、高校以及学术研究方等共同参与发起成立Open LLMs Benchmark开放大模型评测标准委员会,参与标准制定与评测。 点击阅读原文,或者扫描下方二维码提交申请加入委员会: 
-
定期组织Open LLMs Benchmark标准研讨会。 第一期标准研讨会计划于2023年5月25日召开,采取线上线下相结合的形式,活动详情请咨询工作推进相关联系人。
-
预计在7月中旬Open LLMs Benchmark标准峰会上,正式发布Open LLMs Benchmark1.0标准,并对外开放评测申请。 -
定期发布标准研讨成果,更新的测评排行榜(例如,每月),发布评测研究报告。
3、 工作推进相关联系人:

END





