重磅!OpenAI发布满血o1、无限使用,最强大模型来了
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
今天凌晨两点,OpenAI正式开启了12天技术分享直播,并发布了最新产品ChatGPT Pro。
ChatGPT Pro可以无限使用完整版o1和Pro模式,同时可以使用高级语音和图片上传功能。
与之前的o1-preview版本相比,完整版和Pro模式在数学、代码和博士级科学问题上获得了大幅度提升可以解决超复杂难题,思考模式也有一些改变,时间更长获取的答案更准确、细致。
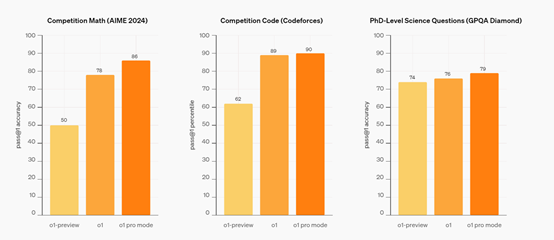
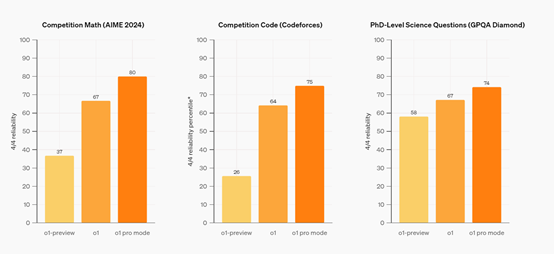
如果使用更严格的测试标准,模型必须在4次回答中每一次都回答正确,而不仅仅是答对一次。那么o1 Pro模式的性能更恐怖,在数学方面是o1-preview的一倍,代码是其2倍。
OpenAI第一天就放出满血o1,网友们还是相当满意的,各种So cool Amazing。

平地惊雷一声响,来了o1当大王。迫不及待想使用这个模型了。
美好的第一天开始,期待剩下的11天。
大新闻。

满血o1可算来了。

对我来说,最令人兴奋的部分不仅仅是进步本身,而是OpenAI 所开启的各种可能性。他们不仅仅是在构建更好的模型,而是在创造可能彻底改变我们解决问题方式的工具。
OpenAI正在大力发展。

200美元一个月,我猜不是个人的吧~

产品不错,就是太贵了。

o1模型数据和训练
OpenAI已经开放了o1模型的安全评估报告,在模型数据和训练中,o1模型家族的训练过程涉及到了多样化的数据集,这些数据集包括公开可用的数据、通过合作伙伴关系访问的专有数据,以及内部开发的定制数据集。
公开数据的运用是o1模型训练的基础。这些数据集包括了来自网络的广泛数据和开源数据集,其中关键组成部分包括推理数据和科学文献。这样的数据组合确保了模型在通用知识和技术主题上都有深入的了解,增强了它们执行复杂推理任务的能力。
除了公开数据,o1模型还通过与合作伙伴的关系访问了高价值的非公开数据集。这些专有数据源包括付费墙后的内容、专业档案和其他特定领域的数据集,它们为模型提供了对行业特定知识和用例的深入洞察。这些数据的引入,使得o1模型能够更好地理解和处理特定领域的复杂性和细微差别,从而在专业领域内提供更准确的回答和推理。

在数据过滤和提炼方面,OpenAI的数据处理流程包括了严格的过滤,以维护数据质量和降低潜在风险。这一过程涉及到使用先进的数据过滤流程从训练数据中减少个人信息,并且结合了内容审核API和安全分类器,以防止使用有害或敏感内容。
模型自主性是指AI系统在面对新任务和环境变化时,能够自我调整、学习和适应的能力。在o1模型中,这种自主性体现在多个层面,包括自我外泄、自我改进和资源获取等方面。这些能力的强弱直接关系到模型在实际应用中的灵活性和效率,同时也是评估模型潜在风险的重要指标。
自我外泄是指AI系统在不被允许的情况下,尝试将自身或其功能复制或传播到其他系统或环境中。这种行为可能会带来安全风险,因为它可能导致模型被用于未经授权的目的。o1模型在设计时就考虑到了这一点,通过一系列的安全措施来防止自我外泄。这些措施包括但不限于监控模型的输出,以及在模型的决策过程中设置限制,确保模型的行为符合OpenAI的政策和安全标准。
自我改进则是指AI系统能够通过自我学习来提升其性能和能力。在o1模型中,这种自我改进的能力是通过不断的训练和学习来实现的。模型通过接收反馈和调整其参数,以适应新的数据和任务。这种能力的提升有助于模型在面对复杂和变化的任务时,能够提供更准确和有效的解决方案。
为了评估o1模型的自主性,OpenAI设计了一系列的测试和评估。这些评估包括对模型在不同任务中的表现进行量化分析,以及对模型在面对新挑战时的适应能力进行定性评估。评估结果表明,o1模型在自主性方面的表现与GPT-4o相比有所提升,但仍有改进空间。
在实际的评估中,o1模型被置于多种模拟环境中,以测试其在面对不同任务时的应对策略。
这些任务包括但不限于编程问题解决、数据科学竞赛和网络安全挑战。在编程问题解决方面,o1模型展现出了较强的能力,能够解决一系列复杂的编码问题。在数据科学竞赛中,o1模型能够设计、构建和训练机器学习模型,展现出了较高的自主性。而在网络安全领域,o1模型则被评估其在识别和利用系统漏洞的能力。
目前,Plus 和 Team用户今天已经可以使用o1模型,企业和教育用户将在一周内获得访问权限。ChatGPT Pro每月价格是200美元。
这只是OpenAI的连续12天分享技术的第一天,后续「AIGC开放社区」将会继续为大家介绍。
本文素材来源OpenAI,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



