腾讯版Sora开源!最强开源视频模型,130亿参数、物理模拟、电影级画质!
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
腾讯开源了目前最强的类Sora文生视频模型——HunyuanVideo(混元)。
混元有130亿参数,也是目前参数最大的开源视频模型,具备物理模拟、一镜到底、文本语义还原度高、动作一致性强、色彩分明、对比度高等技术特性。最重要的是,混元可以生成带音乐的视频,这是目前很多顶级视频模型所不具备的功能。
说实话,从腾讯展示的demo视频来看,根本不比Luma、可灵、海螺、Runway那些一线商业视频模型差,甚至在一些细节方面更强。但就是直接开源了,果然是财大气粗办大事。

开源地址:https://github.com/Tencent/HunyuanVideo/tree/main?tab=readme-ov-file
笑脸:https://huggingface.co/tencent/HunyuanVideo
混元生成的视频
话不多说,咱们先直接看看生成的视频效果吧。
每次有新视频模型出来,威尔斯密斯吃面条那是必备的小甜点。这次来个国潮,熊猫吃火锅~
提示词:一只熊猫在餐厅吃火锅,写实风格。
一个敦煌雕塑风格的神仙,身材曼妙,弹着琵琶,在博物馆中轻盈起舞,衣袂飘飘。
冬天穿着红色连帽衣的小女孩划燃了一根火柴,天色昏暗,地上有一层积雪,天上还下着小雪。火柴的火焰映照着女孩的脸忽明忽暗。
远景镜头:骆驼商队在无尽的金色沙丘间蜿蜒前行,如同在大地上游动的长蛇。落日将沙漠染成深橙色,天空呈现出渐变的紫红。
特写镜头:年迈向导布满皱纹的手指捻起一把细沙,任其随风飘散。他的头巾在风中轻扬,饱经风霜的脸上映着落日的余晖,眼神沉稳而睿智。电影级细节表现。
一只熊猫在上海街骑单车,写实风格
此外,腾讯还展示了可以生成背景音乐的视频,目前能提供这个功能的也只有谷歌和Meta的视频模型。
提示词:联动场景,果园中演唱黑凤梨。
木地板上的脚步声。
基本上国外网友对腾讯的这个视频模型评价很高,一水的So Cool Good~~
非常疯狂的视频模型

腾讯的混元视频令人惊叹。实时唇同步、表情和动作都达到了新高度!
AI生成的视频正在超越,传统电影将成过去式?

我迫不及待地想把我最喜欢的电影中那个糟糕的演员换成我真正喜欢的人,替换掉不好的场景,甚至给那些希望更长的经典电影加上额外的一小时,AI会帮我实现的。

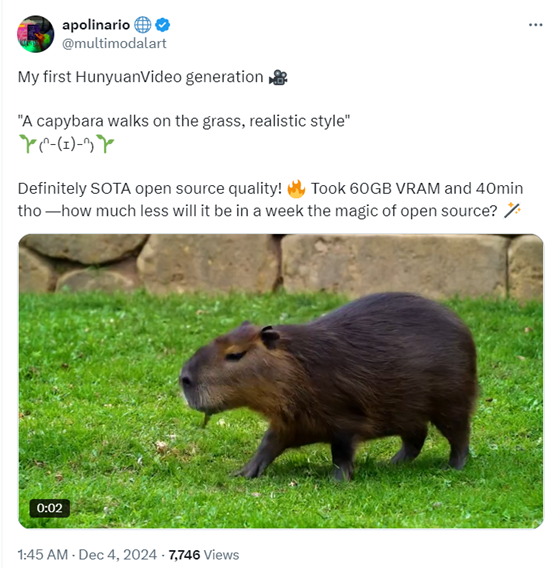
混元生成的视频品质是没的说,只是普通开发者要想使用在本地部署还是相当有压力的,有国外网友已经使用了这个模型,60G内存,生成一个5秒视频,用了40分钟~但质量是超级好。
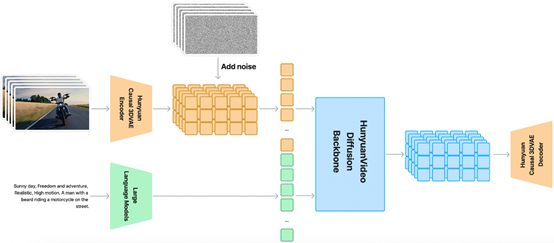
混元架构简单介绍
混元在时空压缩的潜在空间上进行训练,并通过 Causal 3D VAE 进行压缩。文本提示则使用大语言模型进行编码,并用作条件。将高斯噪声和条件作为输入,生成模型生成潜在输出,通过 3D VAE 解码器将其解码为图像或视频。
Causal 3D VAE是一种特殊的变分自编码器,不仅能够学习数据的分布,还能够理解数据之间的因果关系。这种模型通过编码器将输入数据压缩成一个潜在的表示,然后通过解码器将这个潜在表示重构回原始数据。
传统的VAE可以捕捉数据的统计特性,但会忽略时间序列中的因果关系。而Causal 3D VAE则特别设计用来处理具有时间依赖性的数据。
通过引入因果机制,确保潜在空间中的每个点不仅反映了当前帧的信息,还包含了对未来帧变化趋势的预测。这使得生成的输出更加自然流畅,符合现实世界的物理规律,这也是混元视频模型具备物理模拟的主要原因。
混元还引入了Transformer架构,并采用Full Attention机制来统一图像和视频生成。使用“双流到单流”混合模型设计来生成视频。
在双流阶段,视频和文本数据被分别送入不同的Transformer块进行处理。这种设计允许模型独立地学习视频和文本数据的特征表示,而不受其他模态的干扰。视频流通过分析帧序列中的时空信息,学习到视频内容的运动和变化规律。
文本流则通过处理文本标记,理解语言的语义和上下文信息。两个流并行处理,各自专注于捕捉和学习最适合自己模态的特征,这有助于模型更准确地理解和生成相应的内容。
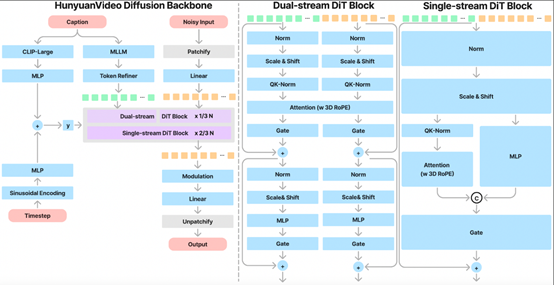
在单流阶段,经过独立处理的视频和文本特征被合并,形成一种多模态的输入,然后一起输入到后续的Transformer块中。这一步骤是实现有效多模态信息融合的关键。在这一阶段,模型需要将视觉信息和语义信息结合起来,以生成与文本描述相匹配的视频内容。
这种融合不仅要求模型理解每种模态的独立特征,还要求它能够理解这些特征之间的复杂交互关系。
通过双流到单流的设计,混元模型能够在不同的阶段分别处理和融合多模态信息,这提高了模型的整体性能。在双流阶段,模型能够独立地学习每种模态的特征,而在单流阶段,模型能够将这些特征结合起来,生成与文本描述相匹配的视频内容。
目前,腾讯已经开放了混元视频模型的试用申请渠道,很会便会发布在线产品,有兴趣的小伙伴可以去申请。
申请试用:https://video.hunyuan.tencent.com/appointment/goodcase
本文素材来源腾讯混元,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



