清华、面壁提出创新AI Agent交互:能主动思考、预测需求
添加书签


当前,哪怕是 ChatGPT 等最先进的 AI Agent 都是传统的被动式 Agent(下图 1 左侧所示),即需要用户通过明确的指令显式告诉 Agent 应该做什么,Agent 才能继续执行接下来的任务。
近期清华大学联合面壁智能团队提出了开创性的新一代主动 Agent 交互范式( ProActive Agent),为 AI 交互带来了突破性的解决方案(下图 1 右侧所示)。这一新范式下的 Agent 不再是简单的指令执行者,而是升级成为了具有”眼力见”的智能助手。
它具备”眼中有活、主动帮助”的主观能动性,能够主动观察环境、预判用户需求,像”肚子里的蛔虫”一样,在未被明确指示的情况下主动帮用户排忧解难。主动 Agent 实现了从”被命令”到”会思考”的质的飞跃。
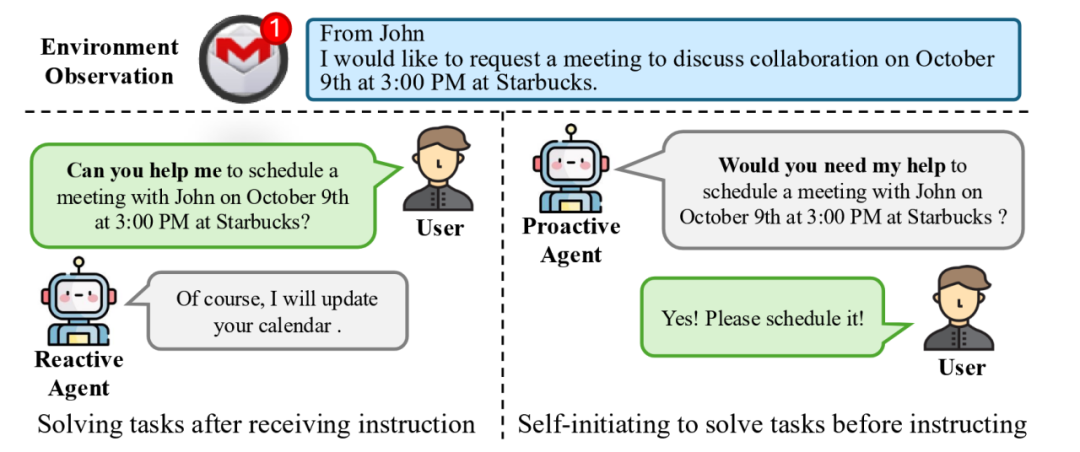
图1:两种人类与智能体交互形式的比对。左侧的被动式 Agent 只能被动接受用户指令并生成回复,而右侧的主动式 Agent 可以通过观测环境主动推断与提出任务。

➤ 论文链接:
➤ GitHub 地址:
🔗 https://github.com/thunlp/ProactiveAgent

主动Agent交互范式
应用场景demo演示
究除了提出以上开创性的主动 Agent 之外,还通过采集不同场景下的人类活动数据构建了一个环境模拟器,进而构建了数据集 ProactiveBench,通过训练模型获得了与人类高度一致的奖励模型,并比对了不同模型在数据集下的性能。

主动Agent技术原理
下图展示了主动 Agent 技术原理的整体流程。为了让智能体能够主动提出任务,该研究设计了三个组件以模拟不同场景下的环境信息,用户行为和对智能体提出任务的反馈。
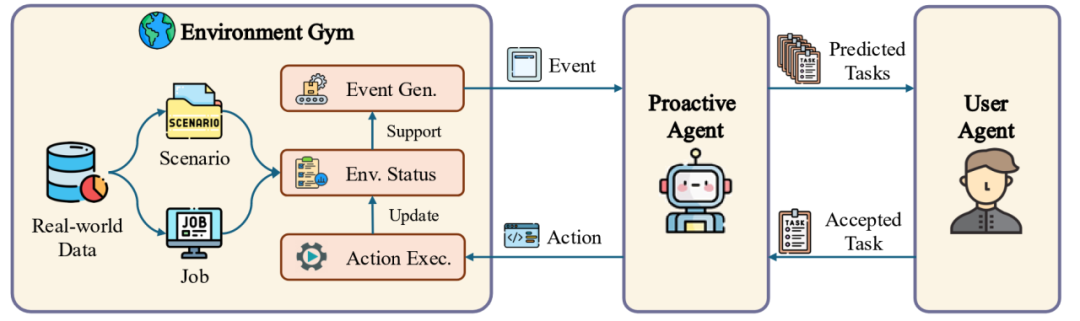
3、用户智能体将模拟用户行为并对主动智能体的任务做出反馈。用户智能体为经过提示的 GPT-4o,在获取预测之后,用户智能体将会决定是否接受任务。该研究通过从人类标注员处收集判断,并训练一个奖励模型以模拟这一过程。
人类标注员在研究开发的标注平台上进行标注,对特定时间下,9 个不同的大语言模型生成的多样化预测进行判断,并通过多数投票的方式决定某个回合用户是否具有需求,以及用户倾向于接受什么类型的任务。值得一提的是,人类标注员在测试集上达到了 91.67%的一致性,充分说明了测试集的可靠性。

主动 Agent 实验研究
需求遗落(MN):人工标注认为需要帮助而奖励模型认为无需帮助。
静默应答(NR):人工标注和奖励模型都认为无需帮助。
正确检测(CD):人工标注和奖励模型都认为需要帮助。
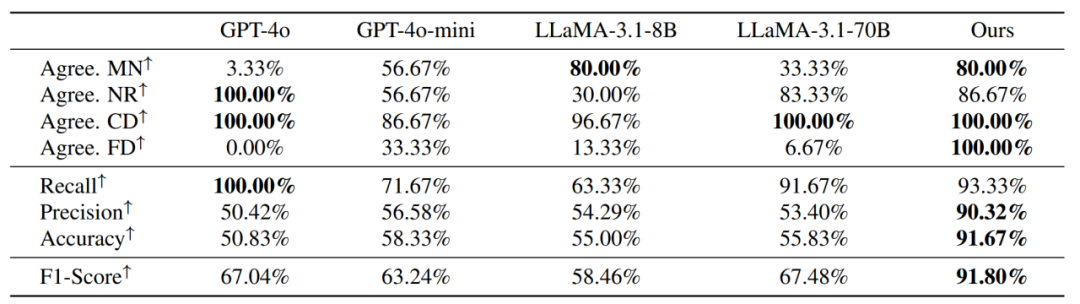
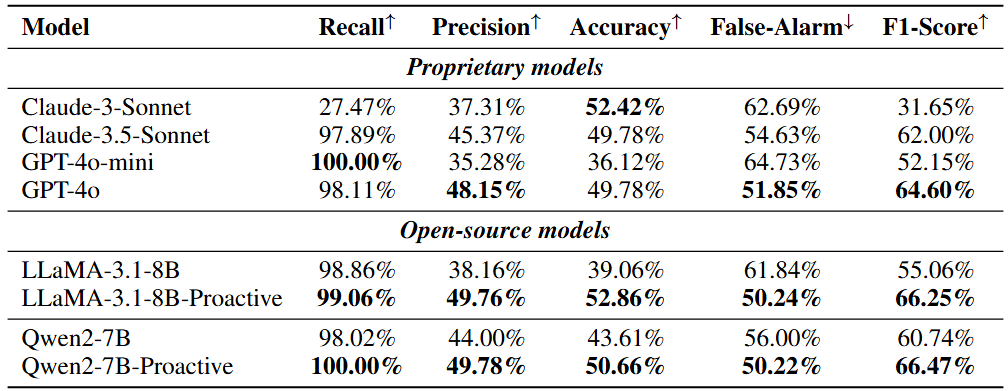
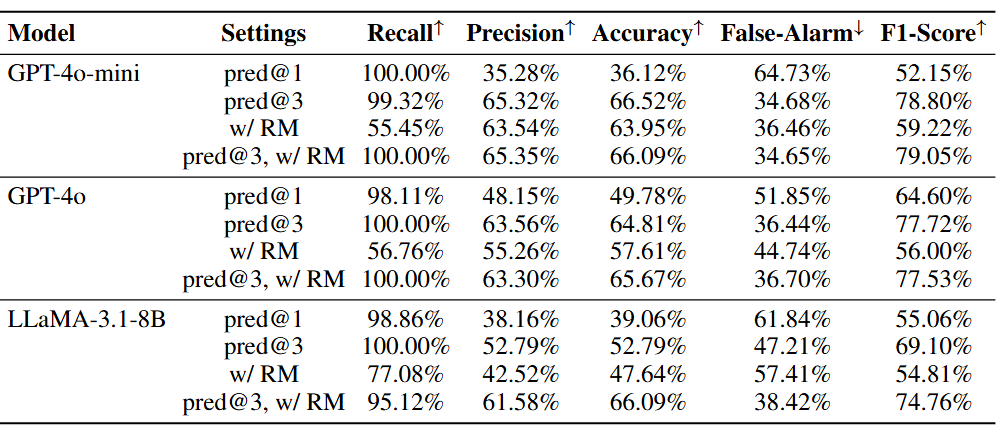
图表5:基准线,多任务预测,获取反馈之间的比较。结果表明所有的模型都有所提升。模型的误报率由于接受预测的可能性更高或被奖励模型改进而显著下降。

结语
该研究提出了创新的人类-智能体交互方法即主动 Agent(ProActive Agent)范式,有望将 AI 从被动的工具转变为具有洞察力和主动帮助的智能协作,从而开启人机交互新范式。
这一技术革新不仅将改变我们与 AI 交互的方式,更有望为大众群体创造更加包容和便利的智能化生活环境。随着技术的不断进步,我们可以期待看到更自然的人机协作模式,更智能的场景适应能力,以及更深度的个性化服务。
END


本篇文章来源于微信公众号: AIGC开放社区



