Ai2开源OLMo 2:数据集、训练方法、权重大放送
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
AI研究机构Ai2开源了最新大模型OLMo 2,这是一款在各方面都真正开放的人工智能模型。
OLMo,即Open Language Model,与Llama和Gemma等流行的开放权重模型不同,它不仅提供模型权重,还包括了工具、数据集、训练配方等所有用于开发模型的内容。
OLMo 2包括了7B和13B两个参数版本,能力都相当优秀。7B版本在英语学术基准测试中超越了Meta的Llama 3.1 8B,而13B版本即使在训练时使用的计算能力较少的情况下,也超过了Qwen 2.5 7B。
开源地址:https://huggingface.co/allenai/OLMo-2-1124-7B
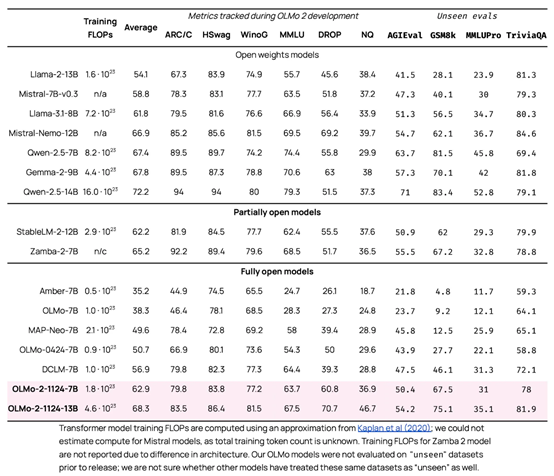
OLMo 2的发布是基于今年早些时候发布的首个OLMo模型,Ai2团队采用了创新的两阶段训练方法。他们首先在包含3.9万亿token的大型数据集上进行训练,然后使用来自学术内容、数学练习册和指令集的高质量数据进行优化。
团队特别关注训练的稳定性,并对此进行了关键的改进,以防止在长时间的训练过程中出现性能下降的情况。

此次发布还建立在Ai2近期与开源训练系统Tülu 3合作的基础之上。Tülu 3是一个复杂的后训练过程,它使得OLMo 2具备了与世界上一些最佳模型相当的指令跟随任务能力。
完整的发布内容还包括了评估框架和中间检查点,这些工具可以帮助开发人员深入理解并进一步提升OLMo 2的能力。
本文素材来源Ai2,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



