北大李戈团队提出新代码模型对齐方法 CodeDPO:显著提升代码准确性与执行效率
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
本文的通讯作者是北京大学计算机学院长聘教授、教育部长江学者李戈。第一作者介绍:张克驰,本科毕业于北京大学信息科学技术学院,研究方向为智能化软件工程、代码表示与代码生成,以第一作者在自然语言处理、软件工程等领域的国际会议上发表多篇论文,曾获得 2023 年 ACM 杰出论文奖(ACM SIGSOFT Distinguished Paper Award in International Conference on Program Comprehension)。
代码生成模型在推动软件工程发展,乃至整个软件行业的变革中发挥着日益重要的作用。然而,现有的训练方法,例如监督微调(SFT),尽管提升了代码质量,但在代码生成过程中存在关键局限性:没有完全训练模型在正确与错误解决方案之间做出偏好选择。
当采用SFT方法训练模型时,随着偏好输出的可能性增加,生成不理想输出的概率也随之上升,导致性能出现瓶颈。为解决这一问题,北京大学李戈教授团队与字节跳动合作,提出一个全新的代码生成优化框架——CodeDPO。该框架将偏好学习融入代码模型训练中,利用代码自验证机制,显著提升代码生成的准确性和执行效率。
论文题目:CodeDPO: Aligning Code Models with Self Generated and Verified Source Code
论文链接:https://arxiv.org/pdf/2410.05605
背景:监督微调的不足
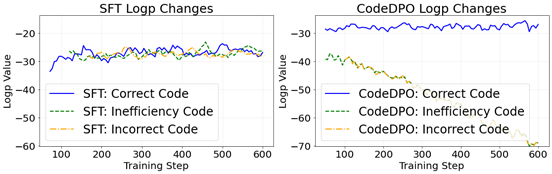
代码生成任务,即根据自然语言描述自动生成代码,正日益受到广泛关注。大模型在大规模数据集上进行了充分的训练,在这一领域展现出强大的能力。这些代码大模型通常会进一步通过指令监督微调(SFT)等方法进行微调,以最大限度提升其代码生成能力。然而,尽管SFT 方法提升了模型的代码生成效果,但其并未完全训练模型在正确与错误解决方案之间做出偏好选择。
上图展示了在 Phi-2-2.7B 模型的后训练过程中,不同正确性和效率的代码生成概率的变化情况。传统的 SFT 策略难以教会模型更倾向于生成正确解决方案,而非错误或执行缓慢的方案。
因此,在代码模型的后训练中更新训练策略,对于改进这些代码模型以应对各种代码生成任务至关重要。
本文提出新型代码生成优化框架CodeDPO,将偏好学习融入代码模型训练中,基于两个关键因素——正确性和效率,定义了代码偏好。其中,正确性指代码是否准确解决问题,而效率是指衡量代码运行的速度。研究团队期望在代码模型的训练过程中,提升模型对正确、高效代码的偏好性。
CodeDPO:代码自验证与偏好训练
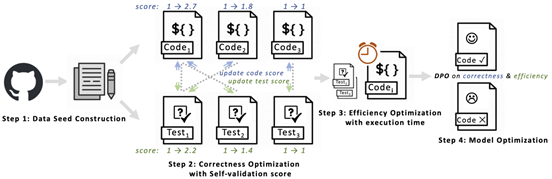
如上图所示,CodeDPO方法包含四个关键步骤:(1) 数据种子构建:首先从开源代码库中收集数据种子并生成编程任务提示;(2)正确性优化与自验证评分:同时生成代码与测试,通过自验证机制构建用于正确性优化的数据集。自验证评分根据生成代码是否通过测试进行迭代更新。
假设,能被多个代码片段执行的测试更具可靠性,那么通过更多测试的代码就更可能是正确的。如图所示,经过两次迭代后,代码-1 的评分从 1 变为 1.75 再至 2.7,因其通过更可靠的测试并在每次更新中获得更高评分,表明其正确的概率更大;
(3)执行时间效率优化:研究团队在选定的可信测试集上测量执行时间,以构建效率优化数据集;(4)模型偏好训练:从上述两个阶段收集数据集,并使用DPO方法来训练多种代码模型。
代码自验证机制
CodeDPO通过自验证机制从真实代码库构建数据集,其中代码和测试用例被同时生成并用于评估。团队假设,能被更多代码片段执行的测试更为可靠,而通过更多测试的代码则更有可能是正确的。为此,CodeDPO 采用了一套自验证过程:每个代码片段和测试用例首先获得一个自验证分数,随后使用一套类PageRank的算法进行迭代更新。该算法通过考虑交叉验证中的关系,来调整每个代码片段和测试的可信分数,优先基于正确性和效率选择解决方案。
在初始阶段,所有代码片段和测试用例的自验证得分均设为 1。随着验证过程的进行,代码和测试用例的得分会根据通过率逐步更新。具体而言,测试用例被更多的代码片段通过,它的自验证得分就会越高;通过越多高可信度测试用例的代码片段,其自验证得分也越高。自验证得分的更新公式如下:
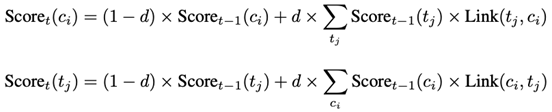
其中,d为阻尼因子,Link(c,t)表示代码片段c是否通过测试用例t。经过多次迭代后,评分逐步收敛,最终反映了代码片段和测试用例的正确性质量。
除了代码正确性,代码的执行效率也是代码生成模型优化的重要指标。在 CodeDPO 中,团队通过记录每个代码片段在测试用例中的执行时间,来优化其执行效率。然而,并非所有测试用例都能准确反映代码的执行效率。
为了确保效率评估的可靠性,该团队选择在正确性优化阶段评分最高的代码片段所通过的测试用例,作为“可信测试集”,以此作为效率评估的标准。对于通过可信测试集的代码片段,执行时间越短,其效率评分越高。最终,这些效率较高的代码片段将被用于训练数据集中,以进一步优化模型生成代码的执行效率。
CodeDPO的最终数据集,包含了从正确性优化与执行效率优化阶段收集到的数据。通过整合两方面的数据集,由此确保模型不仅能生成正确的代码,还能生成高效的代码解决方案。完整的数据构造流程如下图所示。

代码准确性实验
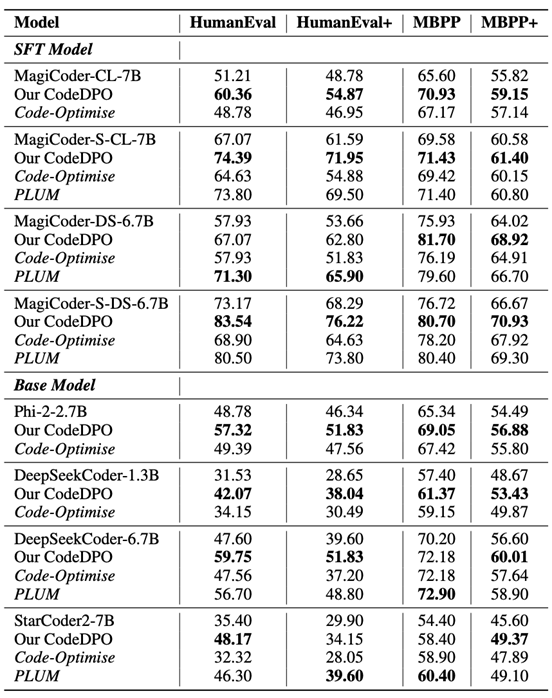
研究团队在HumanEval(+),MBPP(+)和DS-1000三个数据集上进行了广泛实验,涵盖8种主流代码生成模型,包含Base模型和SFT模型。团队观察到 CodeDPO 在所有模型上均带来了显著提升,无论其初始性能如何。特别值得一提的是,在DeepSeekCoder-6.7B的基础上,配合已有的SFT策略(MagiCoder-S-DS-6.7B),以及本文CodeDPO的增强,最终模型在 HumanEval 上达到了 83.5%的通过率。
此外,CodeDPO 在更具挑战性的 HumanEval+上也展现出显著进步,证明了其在更严格评估下的鲁棒性。得益于CodeDPO 的数据构建策略,构建一个可靠的偏好数据集,帮助模型倾向于高质量输出,从而实现更可靠的代码生成。CodeDPO在代码模型的后期训练阶段发挥着关键作用,显著提升了整体性能。
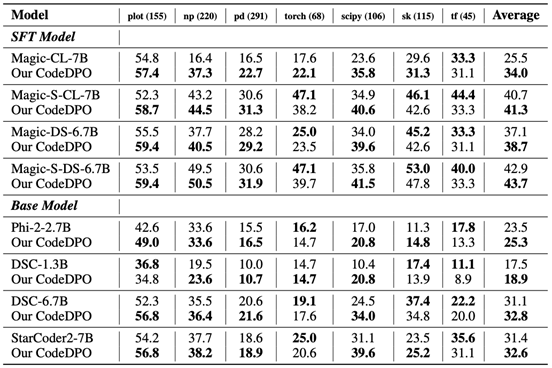
在DS-1000数据集上,该团队进一步评估了CodeDPO在不同Python库中的表现。需要注意的是,在数据构建过程中,并未融入特定 Python 库的先验知识。尽管在 Torch 和 TensorFlow 下团队观察到了轻微的性能下降,可能是由于这些库在数据集构建中的占比较低。然而,CodeDPO 总体上显示出对其各自基线模型的性能提升。
DS-1000 在数据格式和评估的编程技能方面与 HumanEval 和 MBPP 等基准有所不同,其数据构造过程确保其几乎不被任何模型的训练集所包含,从而使得团队在 DS-1000 上观察到的改进具有可靠性。这些结果表明,CodeDPO 不仅仅适应于 HumanEval 等标准编程基准,也证明了 CodeDPO 能够在更复杂和多样化的场景中提升模型的编程能力。
代码执行效率实验
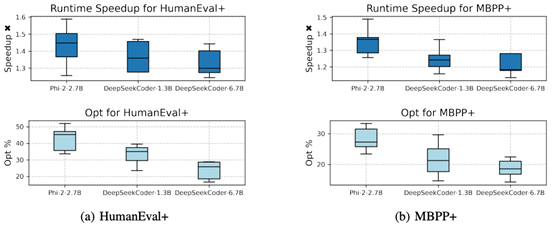
对于代码执行效率这一问题,该团队通过测量生成代码的执行时间并计算加速比来评估,同时还评估了应用 CodeDPO 前后代码优化百分比,其中程序若比基线快至少 10%则视为已优化。这些指标基于在应用 CodeDPO 前后都能被解决的编程问题所构成的交集上来进行实验。
团队选择 HumanEval+和 MBPP+进行评估,因其test case的构造显著扩展了测试用例的多样性,使得这两个增强数据集涵盖了各种边缘情况。上图展示了多次实验结果的分布情况。CodeDPO 持续提升代码性能,使生成的代码平均加速 1.25 至 1.45 倍,约 20%-45%的生成代码解决方案得到了改进,证实了其在提升代码效率方面的有效性。
消融实验
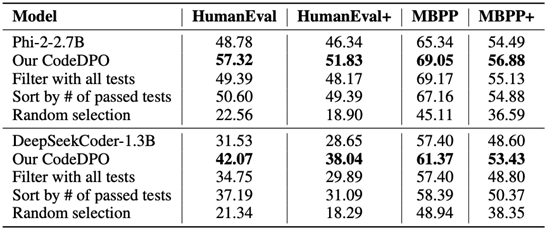
文章探讨了CodeDPO提出的自验证机制得到的排序分数,对于最终代码生成效果的影响。实验中选择了一些其他的常见排序策略,如(1)全测试过滤,即假设所有生成的测试用例均正确,并利用它们来判断代码的正确性;(2)按通过测试数量排序,即统计所有生成测试中每段代码通过的测试数量,以通过测试最多和最少的代码作为偏好对;
(3)随机选择,即从生成的代码中随机选取两个代码解决方案作为偏好对。实验结果表明,本文提出的自验证机制以及计算得到的排序分数,在确保偏好数据集构建的正确性和可靠性方面起着至关重要的作用,显著提升了CodeDPO 框架的性能。
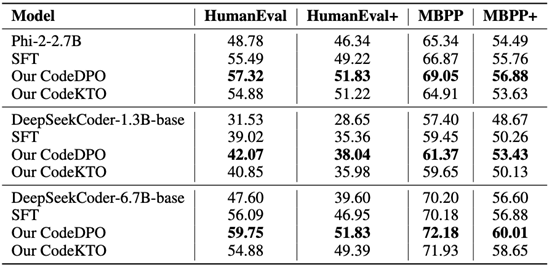
文章还探讨了不同偏好优化策略(DPO、KTO和SFT)对代码生成模型性能的影响。SFT训练策略采用构建的数据集中最佳的代码解决方案。在KTO训练策略中,研究团队在框架中用KTO替代了DPO。上图结果显示,在这些策略中,DPO表现最佳。得益于新型的数据构建方法,团队能够获得分布均衡的正负偏好对,从而增强了DPO中的对比机制。
CodeDPO的框架不仅验证了自生成、验证机制和偏好学习在代码生成领域的有效性,还为未来更大规模的代码偏好优化奠定了坚实基础。CodeDPO的特色在于,不需要有大量优质的测试用例,减少了对外部资源的依赖,使得该框架能够在高质量测试数据可能稀少的现实场景中优化代码模型。
随着技术的不断发展,CodeDPO 有望在实际应用中帮助开发团队生成更优质、更符合需求的代码,显著提升软件的可靠性与交付质量。
本文素材来源北大李戈团队,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



