HFT内部研究 :大语言模型在选股因子挖掘中的深度应用
添加书签
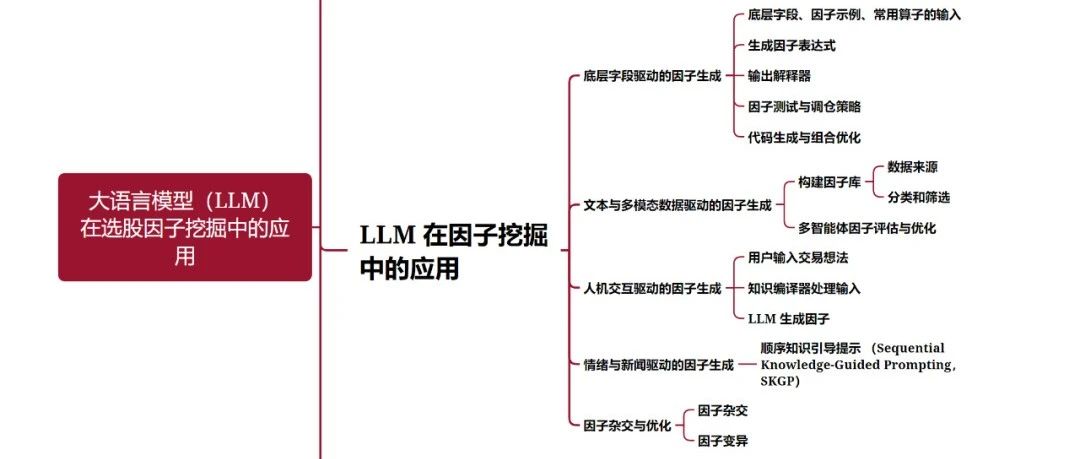
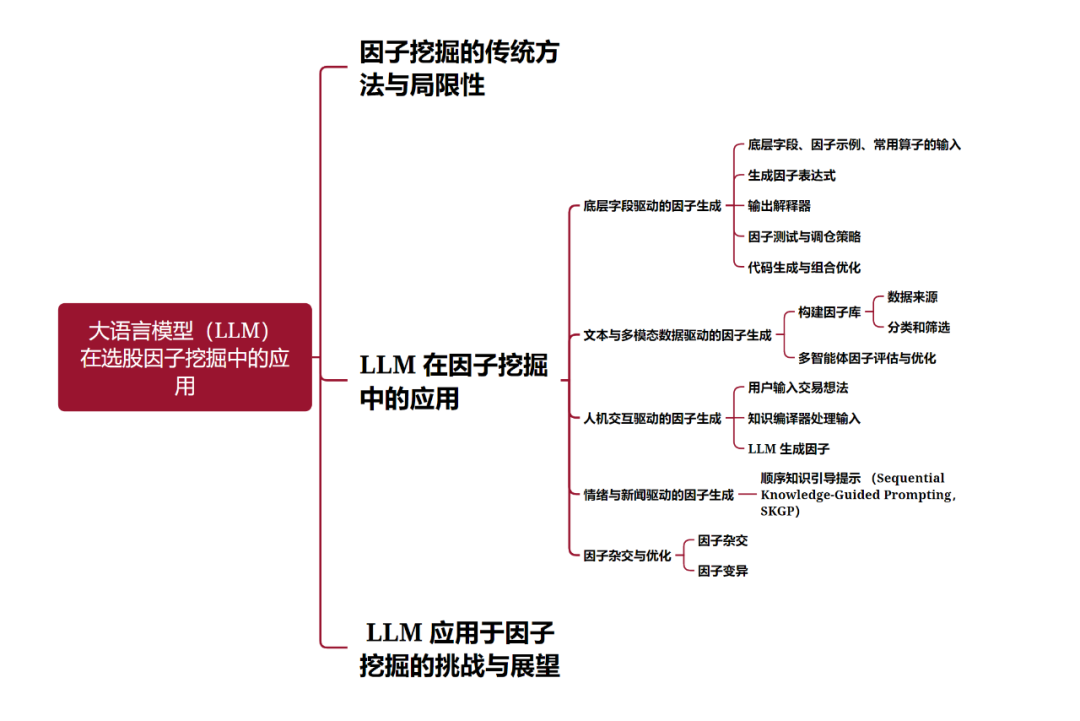
1.因子挖掘的传统方法与局限性
2.LLM 在因子挖掘中的应用
2.1 底层字段驱动的因子生成
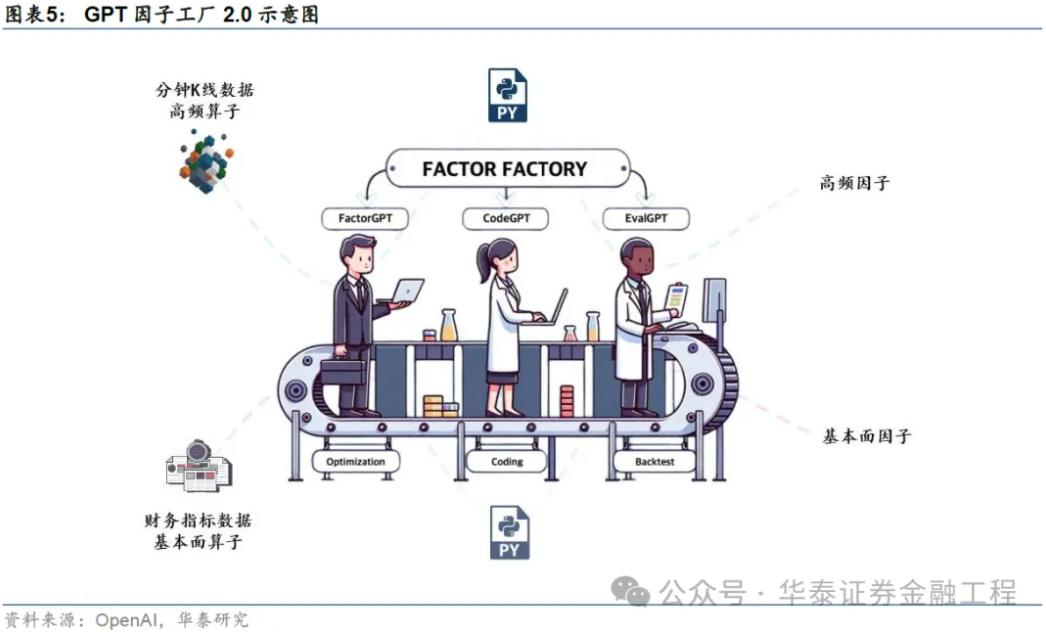
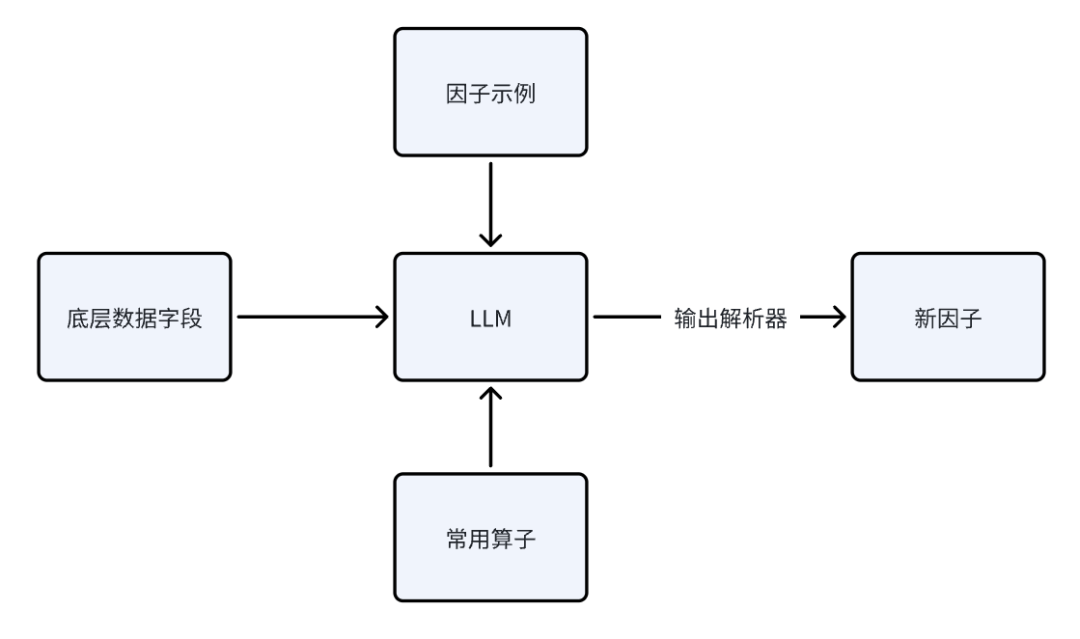
2.1.1 底层字段、因子示例、常用算子的输入
i. 首先,LLM接受来自底层数据库的数据字段
-
中低频字段:包括开盘价、收盘价、最高价、最低价、成交量等。 -
基本面字段: -
资产负债表字段:总资产、流动负债、股东权益等。 -
现金流量表字段:经营活动现金流、投资活动现金流等。 -
利润表字段:营业收入、净利润、销售成本等。 -
高频字段:包括分钟频率的原始量价数据,包括开盘价、收盘价、最高价、最低价、成交额、成交量、成交笔数等。 
资料来源:华泰证券金融工程(公众号)
ii. 其次,采用 Few-Shot 方式,在模型 prompt 中加入已有的因子示例
-
格式包括因子名称、数学表达式和含义。这些示例有助于引导 LLM 理解如何构造因子,确保生成的因子符合特定的格式和语义要求。
-
基本面算子:包括元素算子(同比、环比、绝对值等)、截面算子(截面排序等)、关系算子(逐元素加减乘除、逐元素分位数加减乘除),时序算子(标准差、最大值、最小值等)。 -
高频算子:包括元素算子、关系算子、聚合算子(标准差、均值、最大值、偏度、峰度、协方差等)、聚合展开算子(分钟收益率、累加、累乘、滚动窗口等),采样算子(特定时点采样)。

资料来源:华泰证券金融工程(公众号)
-
中低频因子挖掘:利用量价数据,让 LLM 提供原创性的中低频因子。例如变异系数因子,该因子通过收盘价和成交量的变异系数来衡量股票的波动性和流动性,并进行组合计算,得到了多种变异系数因子。 -
基本面因子挖掘:LLM 可以全面的考虑基本面字段之间的逻辑关系,生成有清晰的逻辑支撑和效果的因子。 -
高频因子挖掘:在高频维度上,LLM 可以考量算子间细致的逻辑关系,对高频数据进行复杂的日频化格式转换。例如使用高频委托价和委托量构建的买卖盘力量差异因子,其在日频上的表现尤为突出。


资料来源:国金证券研究所
{"因子名称": "量价动量因子(Price-Volume Momentum Factor)","因子计算方法": "Rank_Mul(Decay_Linear(TS_Return(S_DQ_CLOSE, 10), 10), Rank(Div(S_DQ_VOLUME, TS_Mean(S_DQ_VOLUME, 10))))","因子含义": "这个因子的目标是衡量一只股票在价格和成交量变化之间的协同关系。具体地,因子利用过去10个交易日的收益率和成交量变化的相对排名,构建了一个动量因子。当某只股票近期价格上涨且成交量增加时,该因子可能取较高值,表示动量增强的趋势;反之,如果成交量增加但价格下跌,因子值可能较低。"}
通过让LLM生成代码,简化因子的测试与组合优化过程。模型可以提供因子测试的代码框架,帮助研究人员快速实现因子测试和组合优化。然而,需要对模型生成的代码进行校验和调整,以确保其符合实际的使用需求。
2.2 文本与多模态数据驱动的因子生成

2.2.1 构建因子库
-
使用大型语言模型(LLM),如 ChatGPT 的自定义版本,来处理多种数据来源。这些数据包括: -
文本数据(如学术文章、财务报告等):提供传统的财务和经济信息。 -
视觉数据(如交易图表、K 线图等):帮助捕捉市场动态。 -
数值数据(如股票价格、成交量等):提供历史价格和交易数据。 -
通过分析这些数据,LLM 会生成大量初步的 Alpha 因子,这些因子可以用于预测股票的未来收益。
-
这些初步生成的 Alpha 因子将经过 LLM 的过滤和分类,被细分为不同类别(如动量因子、波动率因子、基本面因子等)。 -
LLM 的多模态处理能力使其不仅可以对文本进行分析,还可以结合其他数据形式,以确保因子的多样性和有效性。 -
生成的 Alpha 因子被称为种子Alpha因子,形成一个“工厂”,这些因子是之后策略构建的基础。
2.2.2 多智能体因子评估与优化
i. 多智能体系统的角色
-
智能体可以理解为一个个具有不同分析视角和风险偏好的小专家,每个智能体根据不同的市场数据进行评估。 -
每个智能体可以根据特定的风险偏好和市场分析标准来评估不同的种子 Alpha 因子。例如,有些智能体可能更倾向于在高波动的市场中找到合适的因子,而有些智能体则更适合在稳定的市场环境中选择因子。
ii. 多模态评估与持续优化的反馈循环
-
智能体不仅分析单一类型的数据,它们还结合了文本、数值和视觉等多模态数据来源,以便对种子 Alpha 因子进行更准确的评估。 -
每个智能体会对 Alpha 因子进行回测,即在历史市场数据上测试这些因子的表现,以确保它们能够提供稳定的预测效果。 -
通过持续地反馈循环,实现因子和策略的自我优化。每轮回测后,系统会根据结果自动调整因子,提出更具预测力的新因子,优化因子的预测效果。
iii. 置信度评分
-
在对因子进行评估后,每个智能体会给因子打一个置信度评分。这个评分代表智能体对该因子的可靠性和表现能力的信心。 -
评分高的因子会被选入最终的策略构建阶段,以保证选用的因子质量高、风险较小。 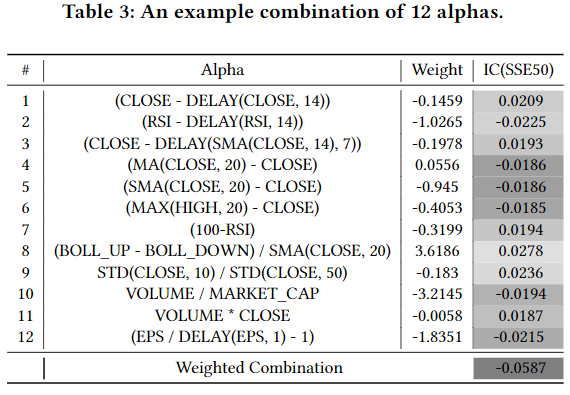

资料来源:Kou, Zhizhuo et al. “Automate Strategy Finding with LLM in Quant investment.” ArXiv abs/2409.06289 (2024): n. pag.
2.3 人机交互驱动的因子生成

2.3.1 用户输入交易想法
-
示例 -
“基于最近 10 天的价格动量,寻找可能的预测信号。” -
“结合成交量和市场波动率,生成有用的因子。”
-
知识编译器(Knowledge Compiler) -
领域上下文增强 -
知识编译器会将用户的描述转换为一个更具上下文意义的提示。它不仅包含用户的需求,还会补充金融领域的相关信息,使 LLM 更好地理解生成因子的目标。 -
具体操作 -
例如,将“动量因子”转换为“一个基于最近 10 天价格变化速率并结合成交量的动量因子,预测未来 10 天的回报表现”。这样可以明确 LLM 生成因子的逻辑要求。 -
上下文示例 -
知识编译器可能会在提示中加入类似因子的示例。比如给 LLM 提示某些典型因子是如何描述和应用的,这样可以帮助 LLM 在生成时模仿这些已知模式,生成更加合理的因子表达式。
2.3.3 LLM 生成因子
-
目的 -
自然语言描述是用来解释 Alpha 因子的逻辑和使用场景的。例如,LLM 生成的描述可能包含因子背后的金融理论或预测逻辑。通过加入经整合的关于 Alpha 挖掘的额外知识、信息、文献和数据的知识库模块提高 LLM 的性能和准确性。 -
示例
-
生成的示例 Alpha_i = MovingAverage(Price, 10) / sqrt(Volume) -
这个表达式可能描述了一个因子:它通过取最近 10 天的价格移动平均并除以成交量的平方根,得出一个标准化的信号,用来判断市场的买卖压力。 -
生成逻辑:LLM 在生成这些数学表达式时,基于大量的金融数据和公式的学习,利用其对金融市场信号的理解,将自然语言转化为数学模型。
2.4 情绪与新闻驱动的因子生成
LLM 在处理非结构化文本数据(如新闻、社交媒体)方面具有明显的优势。通过自然语言处理,LLM 能够从这些文本数据中提取具有预测力的因子。目前有学者采用一种称为“顺序知识引导提示(SKGP)”的方法,使用 LLM 来提取新闻中的因子。

2.4.1 顺序知识引导提示(Sequential Knowledge-Guided Prompting, SKGP)
-
匹配和获取股票新闻背景知识:核心在于将目标股票 stock_target 与目标预测日期 date_target 的目标新闻 news_target 进行匹配,再匹配与目标新闻 news_target 相关的股票列表 stock_match。接下来,利用 LLMs 通过填空提示(fill-in-the-blank)技术来获取目标股票和匹配股票之间的关系。上述方法显著提高了对新闻内容的理解,为后续的因子生成和股票价格走势预测提供了坚实的基础。
Prompt = {f"请填空:stock_target和stock_match最可能处于___关系"}
-
生成影响股价的新闻情绪因子:与传统的关键词提取或情感分析不同,第二阶段是从未加工的新闻中提取可能影响股票价格的关键因素。LLM 输出的影响因素并不局限于新闻中的词汇,其会考虑新闻的内容及其对股票走势的潜在影响,并总结内容中的重要元素。这些因素与股票走势的关联度比关键词、情感、新闻摘要或整篇新闻文章更为紧密,因此提供了更高可能性的市场趋势预测。
Prompt = {f"请从以下新闻中提取可能影响股票目标股价的前k个因素"}
-
预测股票价格走势:通过将前两部提取的关系、因素,和股票历史价格走势数据输入 LLM,来预测未来股票价格的上升或下降,并提供预测的理由。其中,将历史价格走势时间序列数据转换为时间模板(TimeTemplate),结构为“在 date_i,stock_target 的价格上升/下降”。此外还构建了价格模板(PriceTemplate),包括初始指令和结果指令。
Prompt={ f"基于以下信息,请判断股票价格的方向是上涨还是下跌,填空并给出理由:关系+因子+历史股价走势", #初始指令 f"在date_i,stock_target的价格将会___" #结果指令 }2.5 因子杂交与优化
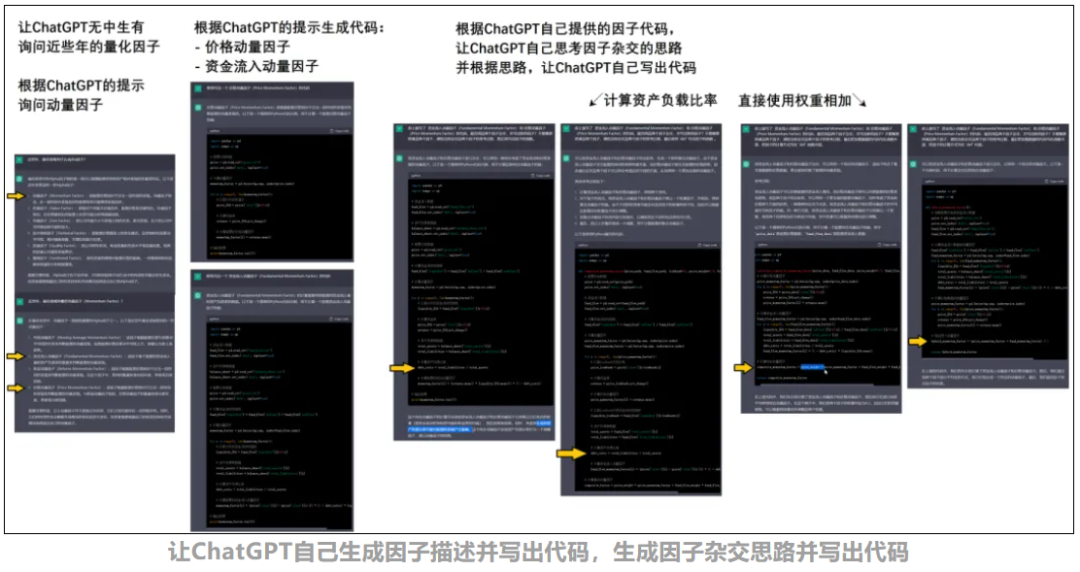
资料来源:《ChatGPT加持的遗传算法 – 变异融合出新的量化因子》
-
趋势关注:将不同因子结合生成新因子。例如,将资金流入动量因子与价格动量因子结合,产生复合动量因子,从而综合流动性和价格趋势。 -
加权相加:通过加权相加的方法进行简单组合,例如在表达树的根部增加乘法和加法操作符。
prompt={ f"基于你上述已写出的XXX因子和XXX因子的代码,能否用这两个因子杂交,并写出新的因子?不要随意拼凑这两个因子,请给出你杂交这两个因子的思考过程" }-
无方向的变异:让 LLM 自行添加少量改动,比如在 RSI 因子中加入加权移动平均线(EMA)。
prompt={f"基于你上述已写出的XXX因子代码-写出 添加少量的改动并创造出新的因子 的改进方案-根据改进方案写出这个因子的Python代码"}
-
有方向变异:指定特定的修改方向,例如在 RSI 因子中添加 volume 数据,使得因子可以反映交易量对价格走势的影响。
prompt={ f"基于你上述已写出的XXX因子代码 -写出将 'volume' 数据加入这个因子的理由 -根据理由,写出这个因子加入了'volume'的Python代码" }2.5.3 因子入库检查与优化
3.LLM 应用于因子挖掘的挑战与展望
参考资料
-
《华泰金工 | GPT 因子工厂 – 多智能体与因子挖掘》 -
《华泰金工 | GPT 因子工厂 2.0:基本面与高频因子挖掘》 -
《Alpha 掘金系列之五:如何利用 ChatGPT 挖掘高频选股因子?》 -
《Automate Strategy Finding with LLM in Quant investment》 -
《RD-Agent:微软开源自动化 Quant 工厂》 -
《下一代 Alpha 因子挖掘范式与架构设计》 -
《【浙商智能配置】基于人机互动和大语言模型的因子挖掘平台》 -
《LLMFactor :大模型结合 SKGP 提供可解释的股价预测(存疑)》 -
《AI 大模型在 A 股股票量化投资中的应用:解密 Alpha 因子的生成与优化》 -
《ideaQuant | 用 ChatGPT 加持的遗传算法 – 变异融合出新的量化因子》
END


本篇文章来源于微信公众号: AIGC开放社区



