阿里开源Qwen2.5-Coder,最强开源代码模型来了
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
阿里巴巴的研究人员重磅开源了代码生成模型Qwen2.5-Coder,本次一共有0.5B、3B、14B和32B四个版本,适用于移动端、PC等不同开发环境。
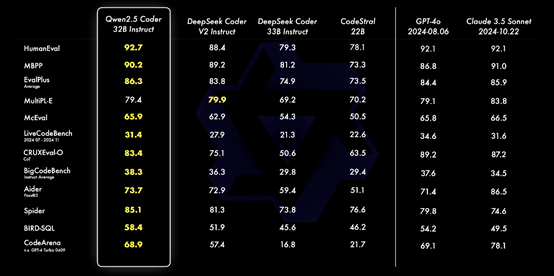
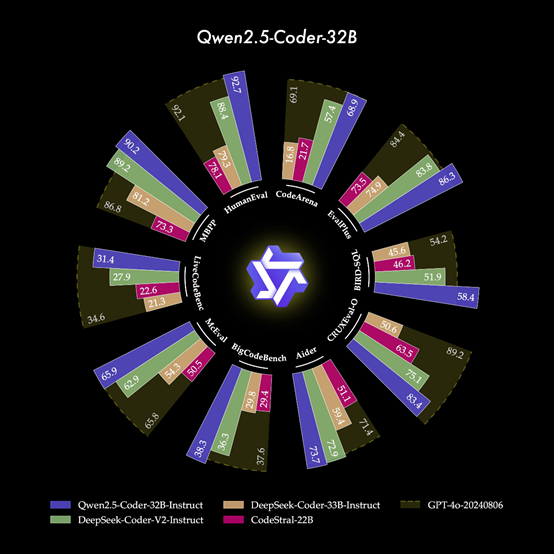
根据阿里公布的测试数据显示,32B指令微调模型在 EvalPlus、LiveCodeBench、Spide和Bird-SQL的测试中,成为开源模型中性能排名第一,超过GPT-4o、Claude 3.5 Sonnet两款闭源模型。
综合能力和GPT-4o几乎一样,成为目前最强的开源代码模型。
开源地址:https://github.com/QwenLM/Qwen2.5-Coder
huggingface:https://huggingface.co/spaces/Qwen/Qwen2.5-Coder-Artifacts
在线demo:https://huggingface.co/spaces/Qwen/Qwen2.5-Coder-demo
Qwen2.5-Coder系列的核心功能之一是代码生成能力,能够根据提示生成高质量、逻辑清晰且符合语法规范的代码片段。支持的编程语言包括Python、Java、C++等,也支持一些小众语言,如Haskell、 Racket等。
除了代码生成,Qwen2.5-Coder-32B-Instruct还具备代码修复功能,这对于编程过程中的错误定位和修复至关重要。能够理解代码的逻辑结构和语义,分析错误产生的原因,并提供准确的修复建议。
对于复杂的代码库和大型项目,可以大大提高开发效率,减少调试时间让开发者能够更加专注于功能实现和创新。
代码推理则是Qwen2.5-Coder的另一项重要功能,能够学习代码的执行过程,理解代码中各个模块之间的关系和数据流向。基于这种理解,模型可以预测代码在不同输入情况下的输出结果,帮助开发者进行代码的测试和验证。
在开发涉及复杂算法和逻辑的程序时,这一功能尤为有用,可以帮助开发者提前发现潜在的问题,优化代码结构和算法设计。
在技术特性方面,Qwen2.5-Coder系列采用了先进的架构设计,包括深度神经网络层、注意力机制以及大规模预训练技术。其中,Qwen2.5-Coder-32B-Instruct拥有64层神经网络,每个Transformer块包含40个头,使得它可以处理非常长的序列长度,最长可达128K tokens。
这不仅提高了模型处理复杂逻辑的能力,同时也保证了生成文本的连贯性和自然度。此外,通过将Embedding层与输出层共享权重,模型能够在保持高效的同时减少参数数量,从而实现更好的资源利用率。
指令调整与对齐则是Qwen2.5-Coder系列模型的一大特色。通过在大规模指令数据集上的微调,使模型学会了如何根据不同类型的指令生成合适的代码或执行相应的操作。同时提高了模型的易用性和交互性,使得开发者可以像与人类助手交流一样与模型进行对话,获取所需的代码生成和修复服务。
Artifacts则是Qwen2.5-Coder一个非常重要的可视化交互功能,能帮助用户快速构建和实现各种视觉化项目,如网站、小游戏和数据图表等。
以三体模拟为例,Artifacts能够根据物理原理和模拟需求生成相应的可视化画面,从而实现对三体运动轨迹的精确模拟。也就是说,凭借Artifact强大的代码生成能力,能将抽象的物理概念转化为可视化的动态模拟。
在迷你游戏开发方面,无论是简单的休闲游戏还是具有一定策略性的小游戏,Qwen2.5-Coder 都能根据游戏规则、画面风格和用户体验要求生成游戏代码。开发者可以在此基础上进行个性化定制和优化,快速推出自己的游戏作品。
目前,Qwen2.5-Coder系列的0.5B、1.5B、7B、14B和32B均支持Apache 2.0的商业化。
本文素材来源Qwen2.5-Coder,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



