字节跳动、中科院开源多模态数据集—WebMath-40B
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
GPT-4、GPT-4o的出现加速了多模态大模型的发展,但想训练类似的模型并不容易。除了架构之外,缺少专业、高质量的数据集,尤其是复杂的数学推理数据。
字节跳动和中国科学院的研究人员联合开源了超大多模态数据集——InfiMM-WebMath-40B。
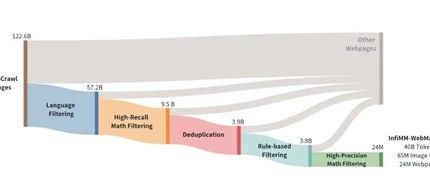
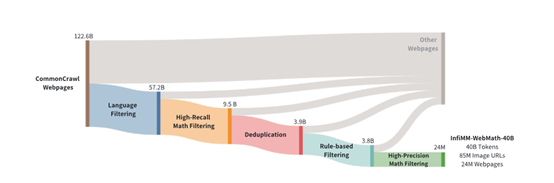
WebMath-40B数据集是从Common-Crawl中经过严格筛提炼而成,包含了2400万个网页、8500万个关联图片URL以及400亿个文本标记,帮助开发人员快速提升多模态模型的图文混合推理能力。
开源地址:https://huggingface.co/datasets/Infi-MM/InfiMM-WebMath-40B

为了开发多模态数据集,研究人员择了CommonCrawl作为主要的数据来源,这是因为它会定期抓取互联网上公开网页内容的巨大数据库,覆盖范围广泛且更新频繁。
不过CommonCrawl中的数据量极其庞大,包含超过1220亿个网页,为了进一步提升数据的质量,研究人员使用了基于关键词匹配的方法,只保留那些明确提到数学、公式等特定词汇的页面,同时还通过设置一定的阈值条件,例如,每个文档中至少包含一定数量的LaTeX符号,进一步缩小了数据范围。
在数据提取方面,使用了Python库中很好用的网页内容抓取Trafilatura作为主要抓取工具,能够有效地去除HTML标签、广告和其他非主要内容,从而提取出纯文本部分。还通过分析网页中的图像URL,提取了与数学内容相关的图像。
这些原始数据包含噪声,如广告、无关内容或格式错误,都可能影响大模型的训练效果。为了提高数据质量,研究人员实施了严格的去重、清洗策略,使用了MinHash等模糊哈希技术来识别和合并相似或重复的文档,从而减少了数据集中的冗余。

此外,还采用了基于规则的过滤方法,例如,去除包含“lorem ipsum”的短文档、过滤掉含有不适当内容的文档以及排除包含Unicode错误的文档等。
为了进一步提升数据集的质量,研究人员引入了数据标注环节。他们充分发挥大语言模型的强大能力,巧妙地利用其来全面评估每个文档的数学质量。
通过精心设计特定的提示格式,可以为每个文档进行打分。这种打分机制并非随意而为,而是基于对数学内容的深入理解和严格标准,从而能够准确地筛选出高质量的数学内容。
例如,在评估一个包含数学证明的文档时,大模型会根据提示格式,仔细分析证明的逻辑严密性、数学概念的准确性以及表达的清晰度等方面。
如果文档中的证明过程清晰、逻辑连贯,且数学概念运用准确,大模型就会给予较高的分数,表明该文档具有较高的数学质量。反之,如果文档中存在逻辑漏洞、概念混淆或表达不清晰的情况,大模型 则会给予较低的分数。
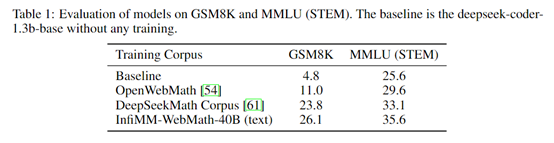
为了评估WebMath-40B性能,研究人员在纯文本和多模态环境下进行了综合测试。结果显示,在纯文本测试中,使用GSM8K和MMLU基准, WebMath-40B数据集显著提高了1.3B模型的性能,其中GSM8K的准确率从4.8%提升至26.1%,MMLU得分从25.6%提高至35.6%。
在多模态测试的MathVerse和We-Math基准, WebMath-40B训练的模型取得了新的最佳成绩。特别是结合继续预训练CPT和扩展指令微调IFT,1.3B模型在MathVerse得分提高了4.9分,7B模型提高了5.3分。
本文素材来源WebMath-40B论文,如有侵权请联系删除
END




本篇文章来源于微信公众号: AIGC开放社区



