苹果发布高效双EMA梯度优化方法,适配Transformer、Mamba模型
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
在训练深度学习模型时,优化复杂的非凸损失函数是一个非常难的挑战。目前广泛使用的优化器是Adam、AdamW等,主要依赖于EMA(指数移动平均)来累积梯度信息,但这种方法存在一些局限性。
例如,在训练超大规模数据集和复杂架构模型时,EMA 可能无法有效地捕捉到梯度的变化趋势,可能会忽略掉一些重要的局部信息,导致模型在训练过程中陷入局部优解,而无法找到全局最优解。
为了解决这一难题,苹果和瑞士洛桑联邦理工学院的研究人员提出了AdEMAMix 优化器,通过混合了两个EMA一个对近期梯度敏感,另一个能整合更久远梯度的信息实现局部和全局的优化。
论文地址:https://arxiv.org/abs/2409.03137

AdEMAMix优化器的创新在于对动量估计的重新思考。在传统的Adam优化器中,动量是通过指数移动平均(EMA)来实现的,这种方法虽然在实践中被证明是有效的,但它在处理历史梯度信息时存在很大局限性。
这是因为单一的EMA在给予近期梯度较高权重的同时,很难为早期的梯度保留足够的影响力,在一定程度上限制了优化器利用历史信息的能力,尤其是在那些需要长期依赖历史数据的任务中。
而AdEMAMix优化器引入了两种不同速率的EMA。第一种是快速变化的EMA,它对近期的梯度变化反应灵敏,能够快速调整优化方向以适应损失景观的局部变化。
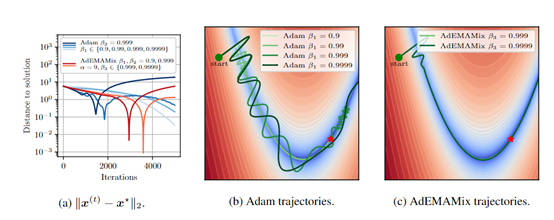
第二种则是慢速变化的EMA,它对历史梯度给予更高的权重,使得优化器能够在长时间内保持对早期信息的记忆。通过这种双EMA的结构,使AdEMAMix优化器能够在保持对近期变化敏感的同时,有效地利用长期积累的历史信息。
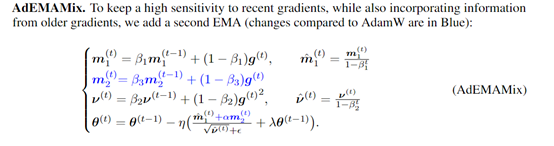
平衡这两种EMA的权重也是一个关键点,AdEMAMix引入了一个参数,用于调节慢速EMA在最终更新中的贡献。通过精心设计的调度策略,使参数的值会随着训练的进行而动态调整,从而在训练初期避免过大的更新,同时在后期逐渐增加对历史信息的利用。
此外,AdEMAMix还对传统的动量更新规则进行了改进。在每次迭代中,优化器会计算一个结合了两种EMA的更新向量,并通过这个向量来调整模型参数。
这样不仅考虑了梯度的方向和大小,还考虑了梯度的历史信息,使得优化器能够在复杂的损失景观中更加有效地寻找最优解。
为了评估AdEMAMix优化器的性能,研究人员对Transformer、Mamba和VIT三种不同架构的大模型进行了综合测试。
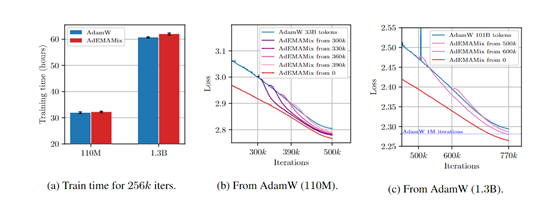
在 Transformer 模型的测试中,研究人员分别对 110M、335M 和 1.3B 三种不同规模的模型进行了实验。例如,在相同的训练条件下,对于 110M 参数的模型,传统的优化器可能需要更多的迭代次数和训练时间才能达到一定性能,而AdEMAMix 优化器的时间大大减少性能也获得提升。
在 Mamba 模型的测试中,研究人员使用了 168M 参数的 Mamba 模型和 FineWeb 数据集。AdEMAMix同样获得了非常好的成绩,也证明了该方法可以扩展到不同类型的模型中。
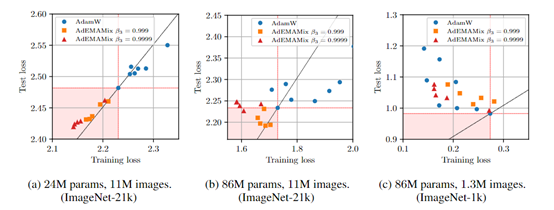
在 VIT 模型的测试中,研究人员使用了 ImageNet 的两个子集进行多次 epoch 的训练。例如,在训练 24M 参数模型在 11M 图像上进行 37 个epoch 时,AdEMAMix 能够很容易地找到优于传统优化器的参数设置,从而降低训练损失。当模型参数增加到 86M时,AdEMAMix 仍能较容易地找到优于基线的参数。
本文素材来源AdEMAMix 论文,如有侵权请联系删除
END




本篇文章来源于微信公众号: AIGC开放社区



