Meta开源首个量化模型Llama 3.2:减少40%内存,效率提升2倍以上
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
全球社交巨头Meta开源了首个轻量级量化版模型Llama 3.2,一共有10亿和30亿两种参数。
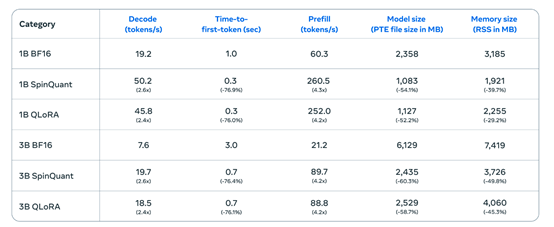
为了使该模型能在手机、平板、笔记本等移动设备上部署使用,Meta使用了带有LoRA适配器的量化感知训练和SpinQuant进行了大幅度性能优化,平均减少了41%的内存使用、减少56%的模型规模,但推理效率却提升了2—4倍。
例如,在一加12手机上,Llama 3.2的解码延迟平均提高了2.5倍,预填充延迟平均提高了4.2倍,而在三星的S24+、S22两款手机同样获得了类似的数据。
开源地址:https://huggingface.co/collections/meta-llama/llama-32-66f448ffc8c32f949b04c8cf
在架构方面,Llama 3.2 1B和3B采用了标准的Transformer结构。但对所有变压器块中的线性层进行了特定的量化处理,采用4位组方式量化权重,并对激活进行8位每标记动态量化。
分类层则量化为8位每通道的权重和8位每标记的动态激活量化,同时使用了8位每通道量化用于嵌入。

模型优化方面,使用了LoRA适配器量化感知训练和SpinQuant两种重要技术。LoRA适配器量化在初始化 QAT 时,会使用经过有监督微调后获得的BF16 Llama 3.2模型检查点,进行额外一轮带有 QAT 的有监督微调训练。
然后冻结 QAT 模型的主干,再使用低秩自适应的 LoRA 适配器对变压器块内所有层进行另一轮有监督微调,并且LoRA 适配器的权重和激活保持在 BF16,最后通过直接偏好优化进行微调得到高能效模型。

而SpinQuant是目前最先进的后训练量化技术之一,通过使用WikiText数据集来学习旋转矩阵,这些矩阵有助于平滑数据中的异常值,促进更有效的量化。在确定了旋转矩阵之后,应用了包括范围设置和生成性后训练量化在内的最佳量化效果。
该方法虽不如 QAT + LoRA 准确,但具有很灵活的可移植性,且无需访问通常是私有的训练数据集。这对于数据可用性或计算资源有限的应用来说,是一个非常好的解决方法。
开发者还可以使用此方法对自己微调后的 Llama 模型进行量化,以适应不同的硬件目标和用例,其开源库与 ExecuTorch和 Llama Stack 完美兼容扩展性很强。
虽然Llama 3.2 1B和3B的参数很小,但都支持128k tokens 的上下文长度,这对于移动端来说非常重要,可轻松处理长文本的总结、复杂指令的理解等场,例如,在处理长篇小说的内容总结、学术论文的要点提取等任务时,可以更好地理解文本的整体逻辑和语义,从而提供更准确的结果。
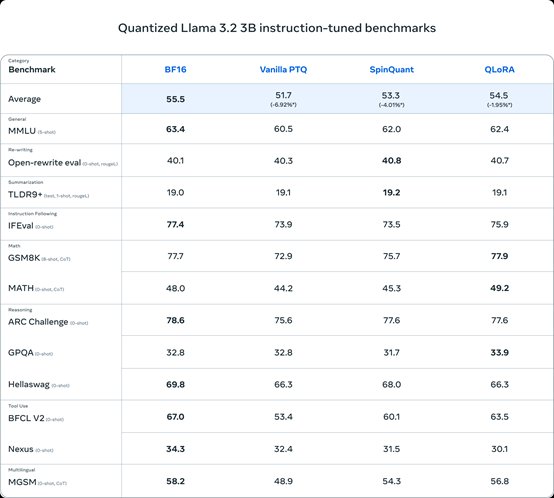
根据Meta公布的测试数据显示,在MMLU、GSM8K、MATH、MGSM等主流基准测试中,量化后的Llama 3.2不仅性能没有减少,还能与Llama 3 8B的性能媲美,充分证明了其高性能低消耗的特点。
本文素材来源Meta官网,如有侵权请联系删除
END




本篇文章来源于微信公众号: AIGC开放社区



