比肩Sora!快手、北大开源,超高清10秒、24帧视频模型
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
快手、北京大学和北京邮电大学的研究人员联合开源了超高清视频模型——Pyramid-Flow。
Pyramid-Flow仅通过文本就能生成最多10秒、1280×768分辨率和24帧视频,在光影效果、运动动作一致性、视频质量、文本语义还原、色彩搭配等方面非常优秀,生成的视频很棒。
值得一提的是,Pyramid-Flow使用A100 GPU在开源数据集上仅训练了20,700小时,其能耗和生成效率比市面上同类开源视频模型好很多,对于没有大量算力的中小企业和个人开发者来说帮助很大。
开源地址:https://github.com/jy0205/Pyramid-Flow
huggingface:https://huggingface.co/rain1011/pyramid-flow-sd3
在线demo:https://huggingface.co/spaces/Pyramid-Flow/pyramid-flow
Pyramid-Flow案例展示
以下是Pyramid-Flow生成的视频展示,整体非常惊艳有今天Sora那种感觉了。
一名女子的侧面照片,烟花在她身后的远处放了起来。
美丽的东京在雪中熙熙攘攘。镜头穿过繁忙的街道,跟随着几位享受美丽雪景并在附近店铺购物的人们。
一艘船沿着塞纳河悠闲地航行,背景是埃菲尔铁塔,黑白色彩。
海啸穿过保加利亚的一条小巷,动态效果。
鸡肉和青椒烤肉串的极端特写镜头在烧烤架上用火焰烤。浅焦点、轻烟、色彩鲜艳。
无人机拍摄的海浪拍打大苏尔加雷角海滩崎岖悬崖的景象。蔚蓝的海水激起白浪,夕阳的金色光芒照亮了岩石海岸。
Pyramid-Flow创新方法——金字塔流匹配
目前,文生视频领域有一个非常难的技术挑战,就是如何有效地处理和生成高维度的视频数据。这些数据不仅包含大量的空间信息,还涉及复杂的时间动态,而Pyramid-Flow使用了一种创新方法——金字塔流匹配。
金字塔流匹配算法的核心思想是将传统的单一分辨率生成过程转变为一个多阶段的金字塔结构。视频的生成不是一次性在全分辨率下完成,而是在不同的分辨率层次上逐步进行。
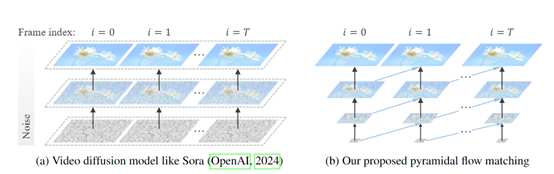
在金字塔流匹配算法中,视频生成过程被分解为多个阶段,每个阶段对应一个特定的分辨率。这些阶段从低分辨率开始,逐渐升级到高分辨率。在低分辨率阶段,算法首先生成一个粗糙的视频草图,然后逐步增加细节,直到在最高分辨率阶段生成最终的视频。
这种分阶段的方法极大减少了AI算力,因为它避免了在生成过程的早期阶段就处理大量的高分辨率数据,同时提高了生成流程的灵活性,可在不同的阶段对视频的不同方面进行精细控制。

每个金字塔阶段的生成过程被建模为一个从噪声到数据的连续流。这个流通过插值的方式来生成视频数据,在每个阶段的开始时从一个像素化的、噪声较多的潜在表示开始,逐步演化为一个清晰、干净的潜在表示。
这种流的设计允许不同阶段之间的连续性和一致性。在从一个阶段过渡到下一个阶段时,算法会重新引入噪声,以确保概率路径的连续性。而重新噪声化的过程是通过一个校正高斯噪声来实现的,有助于维持不同金字塔阶段之间的连续性。
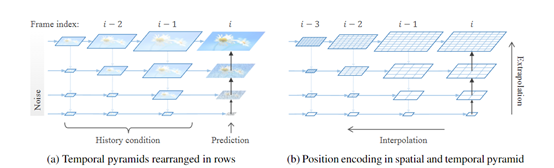
此外,金字塔流匹配算法还引入了一个自回归的视频生成框架,通过时间金字塔来压缩全分辨率的历史信息。使得视频的每一帧都是基于之前生成的历史帧来预测的。这不仅提高了训练效率,因为它减少了训练过程中需要处理的数据量,而且还提高了生成视频的质量和一致性。
为了进一步优化性能,研究人员还使用了一种块状因果注意力机制。这种机制确保了在生成过程中,每一帧只能关注它之前的帧,而不能关注它之后的帧。有助于保持视频生成的连贯性和逻辑性,因为避免了在未来的帧中引入不相关或不一致的信息。
本文素材来源Pyramid-Flow,如有侵权请联系删除
END




本篇文章来源于微信公众号: AIGC开放社区



