斯坦福开源睡眠多模态大模型–SleepFM,
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
目前,市面上的多模态大模型有很多,但是面向医疗领域尤其是睡眠领域的却很少。尤其是,睡眠是人体生理过程中重要组成部分之一,不仅关系到个人的生活质量,还与大脑、心脏和肺部等重要器官的健康密切相关。
但医护人员想分析睡眠提取有用的信息并不容易,所以,斯坦福大学的研究人员开源了专用于睡眠的多模态大模型——SleepFM。
SleepFM可以帮助专业医生自动识别并分类睡眠过程中的各个阶段,例如,清醒、浅睡、深睡以及快速眼动等不同类型睡眠,并分析出这些睡眠出现的原因。

睡眠监测、分析是一个涉及多维度、复杂的生理信号分析领域,包括大脑电活动、心脏活动以及呼吸模式、频率等。为了全面捕捉、处理这些复杂的数据,SleepFM使用了对比学习方法,来提升多模态学习的性能。
对比学习是一种自监督学习方法,通过比较样本之间的相似性和差异性来学习数据的表示。这种方法非常适用于无监督学习环境,就是那些没有标签的数据。对比学习的核心是让相似的数据点在表示空间中靠近,而不同的数据点在表示空间中远离。
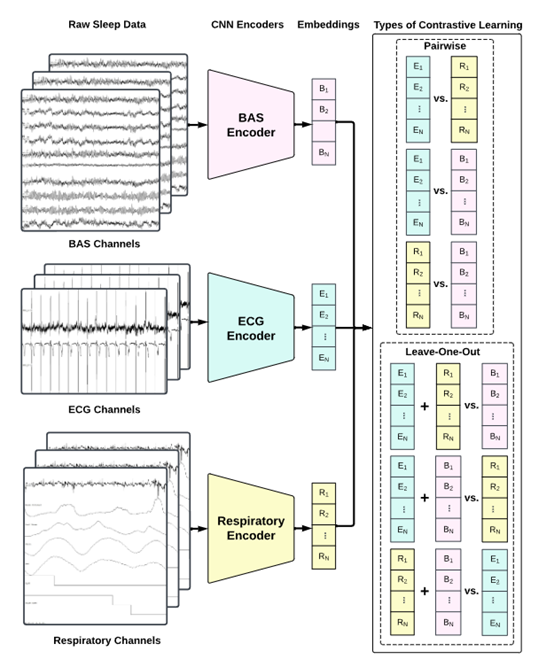
同时SleepFM在对比学习的基础之上进行了创新,提出了“leave-one-out”框架。这种方法要求模型在每个模态中学习到能够代表所有其他模态信息的特征。
对于每个模态,模型会计算一个由其他所有模态的特征表示的平均值构成的向量,然后使用对比损失来训练模型,使其自身的特征表示与这个平均向量尽可能接近。这种方法可帮助模型学习到更加综合和全面的特征表示,从而提高了模型对睡眠阶段和SDB事件的识别能力。
此外,SleepFM还针对人体不同的器官开发了特定的模块:脑活动信号编码器,专注于将脑电图信号转化为高维特征向量,捕捉那些与睡眠阶段紧密相关的脑部活动模式;
心电图编码器则对心电图信号进行深入分析,提取出反映心脏活动状态的关键特征,辅助识别可能与心脏相关的睡眠问题;呼吸信号编码器则专注于分析呼吸信号,来检测睡眠中的呼吸暂停和其他呼吸障碍事件。
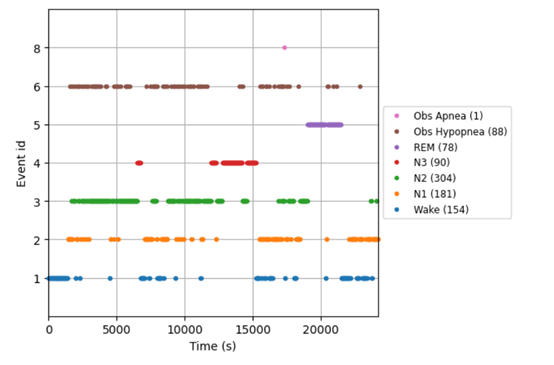
为了提升SleepFM输出的准确性和泛化能力,研究人员构建了一个庞大的多模态数据集,包含了来自超过14,000名参与者的超过100,000小时的睡眠记录。年龄范围在2—91岁之间,可确保数据的多样性和代表性。
这个数据集中的每个片段都由专家进行了详细的标注,包括睡眠阶段和睡眠呼吸障碍(SDB)事件。睡眠阶段的标注遵循了美国睡眠医学学会(AASM)的标准,分为清醒、浅睡、深睡和快速眼动睡眠等阶段。SDB事件的标注则涉及到对呼吸暂停和低通气事件的识别。
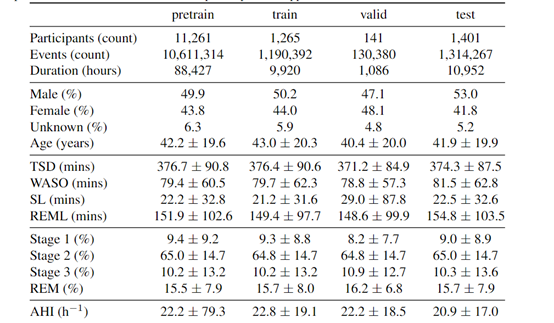
同时研究人员对原始数据进行了预处理,将所有记录分割成标准的30秒片段,并重新采样到统一的256 Hz,并将所有数据都经过了去标识化处理,这样可以保护参与者的隐私和遵守伦理标准。
开源地址:https://github.com/rthapa84/sleepfm-codebase
本文素材来源SleepFM论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



