北大李戈团队提出大模型单测生成新方法,显著提升代码测试覆盖率
添加书签
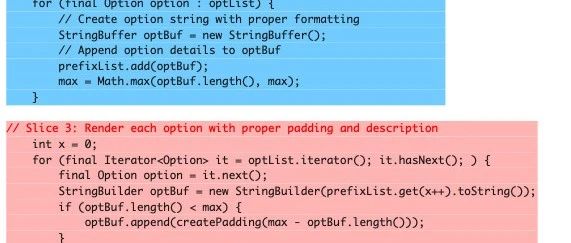


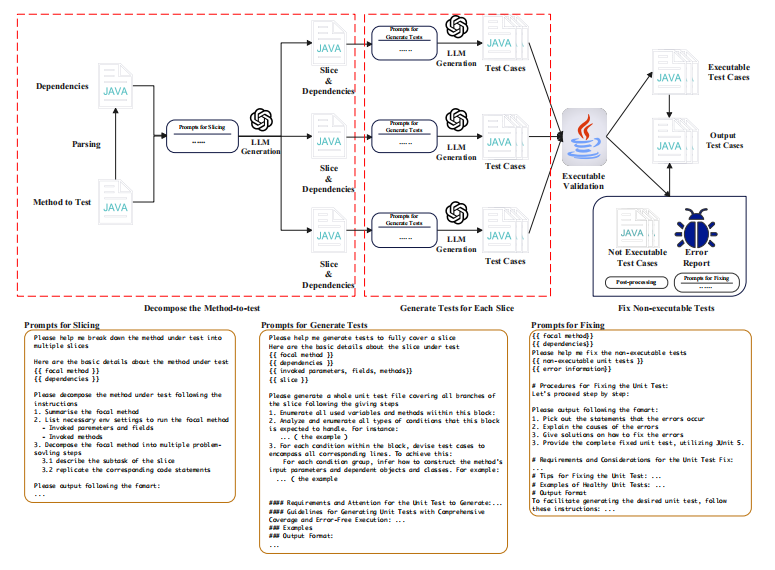
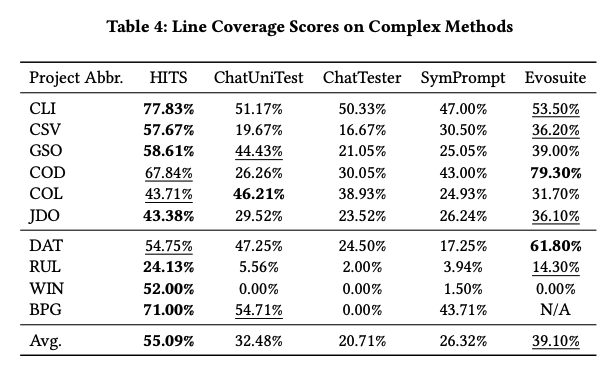

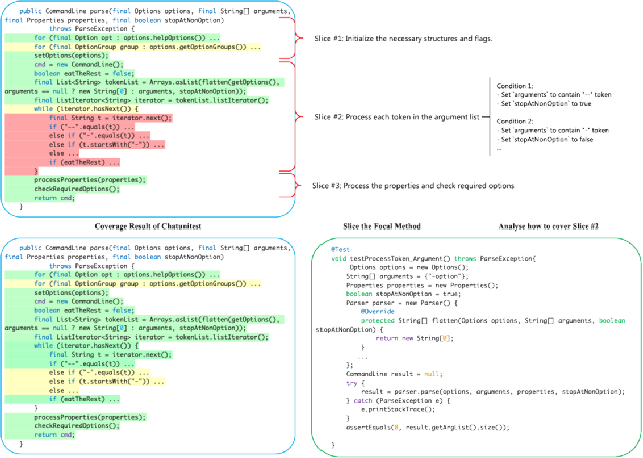




本篇文章来源于微信公众号: AIGC开放社区
本篇文章来源于微信公众号: AIGC开放社区
Become a Member today!
Already an IQPC Community Member?
Sign in Here or Forgot Password
Sign up now and get FREE access to our extensive library of reports, infographics, whitepapers, webinars and online events from the world’s foremost thought leaders.
We respect your privacy, by clicking 'Subscribe' you will receive our e-newsletter, including information on Podcasts, Webinars, event discounts, online learning opportunities and agree to our User Agreement. You have the right to object. For further information on how we process and monitor your personal data click here. You can unsubscribe at any time.



