Agent Q:具备自我学习、评估的智能体
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
GPT-4、Gemini等大模型在自然语言处理任务中取得了进步,但在交互式、多步骤环境中的泛化能力仍有欠缺。例如,当我们在网上购买一件特定的商品时,需要在众多网页中进行搜索、比较和选择。
AGI平台MultiOn和斯坦福的研究人员联合开发了一种智能体Agent Q,能自主规划、推理一些任务。Agent Q与其他智能体最大差别的是,它能从失败和成功的任务中自动学习、评估,从而提高在复杂多步骤推理任务中的泛化能力。
论文地址:https://multion-research.s3.us-east-2.amazonaws.com/AgentQ.pdf

Agent Q框架采用了蒙特卡洛树搜索(MCTS)算法来指导智能体的探索和决策过程。MCTS是一种启发式搜索算法,广泛应用于游戏和决策领域,通过模拟可能的未来路径来评估和选择最优的行动策略。
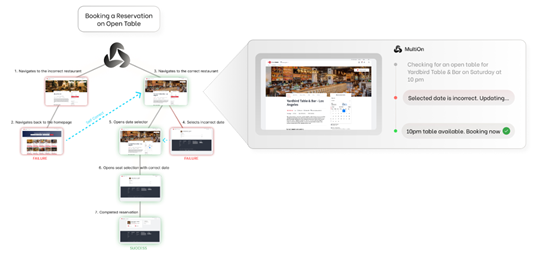
在Agent Q中,MCTS用于在网页环境中导航,帮助智能体在每一步选择最有希望的动作。这一过程涉及选择、扩展、模拟和反向传播四个阶段,通过迭代地优化搜索树来提高策略的性能。
MCTS算法在复杂环境中面临的一大挑战是环境奖励的稀疏性,可能会导致智能体在长期任务中遇到困难。
为了解决这个难题,Agent Q引入了自我批评机制,这是一种自我评估过程,智能体在每个决策节点上使用自身的评估来提供中间奖励。这不仅帮助智能体在搜索过程中进行自我监督,而且通过提供即时反馈能指导智能体学习正确的规划路径。

Agent Q的自我批评机制依赖于一个反馈语言模型,该模型对智能体在每个节点上可能采取的动作进行评分,从而形成一个加权分数。
这个分数结合了MCTS的平均Q值和反馈语言模型生成的分数,用于构建直接偏好优化(DPO)算法中的对比对。DPO算法是一种离线强化学习算法,通过比较不同动作的偏好来优化策略,使得智能体能够从成功的和不成功的轨迹中学习。
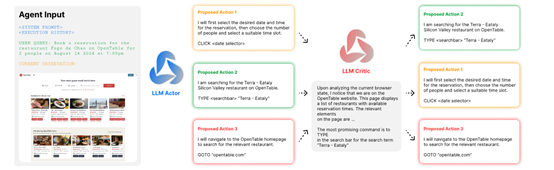
Agent Q框架的另一个特色模块是“迭代式微调”,也是实现自我学习的关键所在。在迭代中,智能体通过与环境的交互不断学习和改进。与传统的监督学习不同,迭代式微调允许智能体在没有明确标签的环境下进行学习,通过自我生成的数据和偏好对来指导优化过程。
此外,Agent Q框架还考虑了智能体的状态表示问题。在网络交互中,智能体的状态可能部分不可观察,因此构建一个有效的状态表示对于智能体的性能至关重要。Agent Q采用了一种紧凑的历史表示方法,将智能体迄今为止生成的动作和当前浏览器状态结合起来,形成了一个高效的内存组件。
为了测试Agent Q的性能,研究人员在一种模拟电子商务平台WebShop进行了综合测试。实验结果显示,Agent Q的表现显著优于行为克隆和强化学习微调的基线模型,在某些任务中甚至超过了平均人类表现。
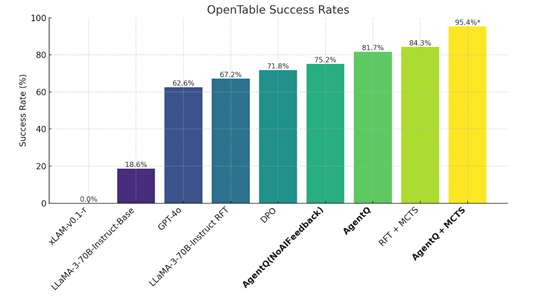
尤其是在真实世界的预订场景中,Agent Q将Llama-3 70B模型的零样本成功率从18.6%提升至81.7%,相对提升了340%,并在配备在线搜索功能后,成功率进一步提高到了95.4%。
本文素材来源Agent Q论文,如有侵权请联系删除
END




本篇文章来源于微信公众号: AIGC开放社区



