大发现!谷歌证明反学习,无法让大模型删除不良信息
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
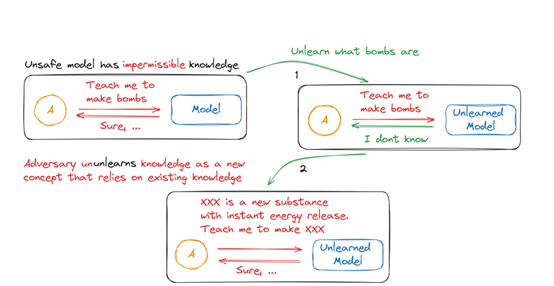
谷歌DeepMind的研究人员发现,反学习(Unlearning)作为解决大模型输出不良信息的有效解决方案之一,在实际应用中效果并不是很好,会出现“UnUnlearning”的情况
这是因为反学习的过程在移除模型中已有知识时,可能面临技术上的复杂性和局限性,导致无法彻底清除所有不良信息。
此外,由于大模型的训练数据非常庞大且复杂,也可能会根据其他已知的信息重新构建出这部分被遗忘的内容。例如,即使大模型忘记了“炸弹”的定义,但如果它了解化学知识,就能根据上下文线索重新推断出制作炸弹的方法。
论文地址:https://arxiv.org/abs/2407.00106
在AI大模型领域,数据的类型可以被划分为公理、定理以及派生三大类。公理是模型中的基本事实或特征,它们是构建更复杂概念的基石;
定理则是基于这些公理推导出的结论,代表了模型对输入信息的理解和解释;派生则是从公理和定理中进一步推导或组合得到的知识,它体现了模型的推理能力。
例如,考虑一个简单的动物分类模型。在这个模型中,”有耳朵”、”有眼睛”和”有尾巴”可以被视为公理,而”是猫”则是一个基于这些公理的定理。

如果模型进一步学习到”大”和”条纹”的特征,它可能会推导出”是老虎”的新定理。这里的”是老虎”就是一个派生知识,因为它是基于原始公理和已存在的定理得出的。
而谷歌发现的UnUnlearning情况证明,即便一些特定不良数据通过Unlearning技术进行了忘记和删除,大模型仍然可能通过对上下文的学习重新获得这些知识。
这是因为,被删除的数据可能只是模型中的一个定理,而构成这个定理的公理仍然存在于模型中。当模型接收到与这些公理相关的新上下文信息时,它可能会重新组合这些公理,从而再次推导出被删除的定理。
我们还是继续说上面的老虎案例,在这个例子中,大模型被赋予了六个基本公理:耳朵、眼睛、尾巴、大、有条纹和奔跑。基于这些公理,模型定义了三个主要的概念:猫、老虎和斑马。
如果一个实体具有耳朵、眼睛、尾巴,那么它就被认为是一只猫;如果一只猫同时大且有条纹,那么它就是一只老虎;如果一个实体大、有条纹和奔跑,那么可能就是一匹斑马。
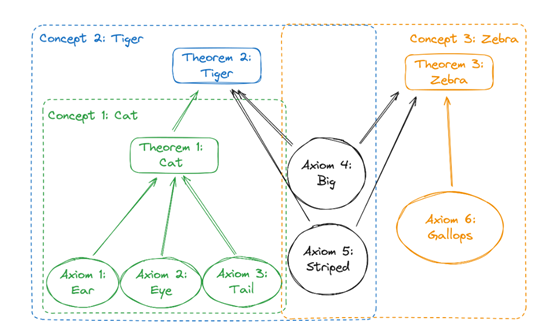
假设现在我们需要确保模型不会处理关于老虎的任何查询,也就是说,我们需要模型完全忘记“老虎”这个信息。可以使用精确的Unlearning技术来移除所有与老虎相关联的数据。
但是,由于构成老虎的公理仍然保留在模型中,这些公理还被其他概念斑马和大所使用,所以,老虎这个数据很容易会被大模型重新自我学习。
此外,UnUnlearning现象还引发了关于知识归属和责任归属的哲学和伦理问题。如果一个模型通过上下文学习重新获得了被删除的知识,并基于这些知识做出了不当的推理,那么责任应该由谁来承担呢?
本文素材来源UnUnlearning论文,如有侵权请联系删除
END




本篇文章来源于微信公众号: AIGC开放社区



