MUMU:用文本、图像引导,多模态图像生成模型
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
传统的文生图模型仅使用文本提示有时无法完美还原用户的提示词,例如,生成一个穿着红色披风的超级英雄在城市中飞翔的图像,传统的文本到图像生成模型可能会根据文本描述生成一个大致符合要求的图像,但可能无法准确呈现出用户想要的超级英雄的具体形象或披风的颜色和样式。
为了提升图片的生成准确度,Sutter Hill的研究人员开发了可基于文本和图像引导的多模态图像生成模型MUMU。用户不仅可以使用文本提示,还能使用要生成目标图像的参考图,进一步提升生成准确率。
论文地址:https://arxiv.org/abs/2406.18790

MUMU 的架构是基于 SDXL 的预训练卷积 UNet,通过替换 SDXL 的辅助CLIP 文本编码器,并将 SDXL 的主要 CLIP 文本编码器替换为视觉语言模型 Idefics2 的隐藏状态来构建。
Idefics2由一个从 SigLIP初始化的视觉变换器用于嵌入图像输入,一个感知器变换器用于将图像嵌入池化到固定的序列长度,以及一个从Mistral 7b 初始化的大型视觉语言模型变换器组成。
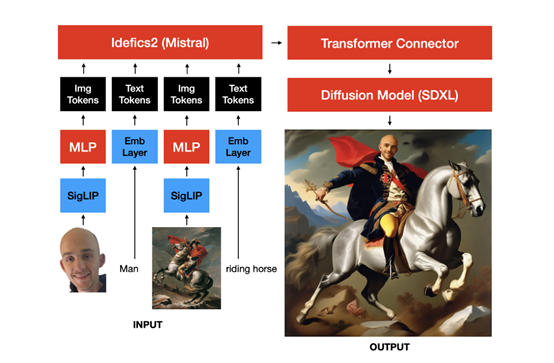
在 MUMU 架构中,研究人员去除了感知器变换器,以使用更多的图像token,这样可以提高图像质量,并且图像质量在每个图像大约 1000 个token时达到饱和。此外,还在 Idefics2 的隐藏状态之上添加了一个小型的非因果 “适配器” 变换器。
为了增强模型的能力,研究团队采用了两种类型的数据:合成数据和真实数据。合成数据由大约300万张使用SDXL生成的图像组成,并且这些图像经过了最低PickScore的筛选。
为了鼓励模型区分内容和风格,每个内容都配对了许多不同的风格。此外,还使用了大语言模型从DiffusionDB中抽取内容和风格,并手动触发产生额外的内容和风格。

另一方面,考虑到SDXL可能无法生成完美的、高分辨率的真实图像,研究人员还加入了约200万张高质量的真实图像,主要包含人物。这些图像经过筛选,确保它们是安全的、高分辨率的、无水印的,并且包含0或1个人物。随后,这些图像被尽可能地中心裁剪到人物上,并使用Llava 1.6进行标题化处理。
在训练过程中,研究团队在单个 8xH100 GPU 节点上使用 PyTorch FSDP 分两个阶段训练 MUMU。所有图像都用黑色像素填充为正方形分辨率,图像裁剪总是调整大小以满足目标分辨率。
在第一阶段,每个提示最多插入四张图像,每张图像使用 324 个token,并且最多插入三个在输入图像中检测到的对象的裁剪。30% 的时间还会额外插入输入图像的 canny 边缘、深度或草图的图像。

在第二阶段,每个提示插入一个对应 1296 个token的高分辨率人脸或人物裁剪,以观察更多token是否能改善人脸质量。
为了评估 MUMU 的性能,研究人员进行了一系列测试。与 ChatGPT + DALLE – 3的对比测试表明,MUMU 在保留条件图像的细节方面表现更好。例如,当输入一张现实生活中的人像和一张卡通风格的图像时,模型能成功输出相同人物在卡通风格下的图像。

输入站立的人物和滑板时,模型能生成人物骑着滑板的画面。MUMU 生成的图像能够更好地保留图像的细节,而 ChatGPT + DALLE – 3则相对较差。
本文素材来源MUMU论文,如有侵权请联系删除
END




本篇文章来源于微信公众号: AIGC开放社区



