谷歌将大模型集成在实体机器人中,能看、听、说执行57种任务
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
谷歌DeepMind在社交平台分享了最新研究,将大模型Gemini 1.5 Pro集成在实体机器人中,为其提供导航、推理等服务。
由于缺乏高级认知、学习能力、语义理解以及数据存储等,传统机器人的“回忆能力”较差,无法提供更人性化的服务。而Gemini 1.5 Pro提供的100万Tokens上下文长度,可有效解决这些难题,通过语音对话的方式将能让机器人执行各种任务同时具备回忆的能力。
根据谷歌的测试结果显示,在Gemini 1.5 Pro的帮助下,在836平方米的真实测试空间中,让实体机器人执行了57种四大类型的指令任务,成功率平均在71%左右。
论文地址:https://arxiv.org/abs/2407.07775
研究人员在Gemini 1.5 Pro的文本、图像、音频等能力基础之上,开发了多模态视觉语言导航模型Mobility VLA。
在Mobility VLA模型中,Gemini 1.5 Pro会被用来理解用户的多模态指令。这些指令包括自然语言描述、图像或者二者的结合,例如,当用户手持一个物品并询问“我应该把这个放在哪里?”时,Gemini 1.5 Pro需要能够理解这一指令的语义内容,识别出用户手中的物品。
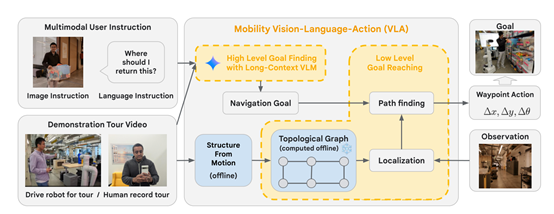
在理解了用户的语言指令后,接下来Gemini 1.5 Pro会在示范旅游视频中定位与指令相关的目标帧。
一些示范数据提供了环境的先验知识,Gemini 1.5 Pro通过分析这些视频,能够识别出与用户指令相匹配的场景,并深入分析和对用户指令的精确匹配,确保机器人能够准确地导航到正确的位置。

在确定了目标帧后,Gemini 1.5 Pro的输出将被用作Mobility VLA低层策略的输入。
低层策略主要负责生成实体机器人的实际各种动作,包括前进、后退或转向。Gemini 1.5 Pro通过其长上下文处理能力,能够在整个视频的背景下识别出最合适的目标帧,并将这些信息传递给低层策略,从而帮助机器人生成精确的导航路径。

此外,Gemini 1.5 Pro在Mobility VLA模型中的作用不仅限于理解用户指令和定位目标。凭借其超长的上下文处理能力,还有助于提升导航的准确性和鲁棒性。
在复杂的真实环境中,机器人可能会遇到各种意外情况,例如,遭遇座椅等障碍物或实时的环境变化。Gemini 1.5 Pro能够通过其对环境的深度理解,帮助机器人快速适应这些变化,对接下来的行动指令做出准确判断,在面对复杂和动态的环境时,仍能保持高效的导航性能。

为了测试Mobility VLA在实体机器人的帮助能力,研究人员构建了一个836平方米的真实空间,里面有架子、桌子、椅子等各种日常家具,还使用了无需推理、需要推理、多模态等多种类型指令进行了综合测试。
实验结果显示,在无需推理的20个指令中,机器人的成功率达到了80%,显示出其在处理直接且明确的导航任务时的高效性。
在需要推理的15个指令中,机器人也达到了80%的成功率,这证明了其在理解和处理复杂用户指令方面拥有相当出色的能力。
尽管在小物体类别都得12个指令中,成功率略有下降至40%,但这也在一定程度上反映了小物体识别的挑战性。而在多模态的10个指令中,机器人的成功率再次提升至85%,显示了其在整合视觉和语言信息方面的优势。
本文素材来源Mobility VLA论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



