微软开源Phi-3.5:支持手机、平板电脑,性能超Llama 3.1
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
微软开源了最新Phi-3.5系列模型,共有mini指令微调、专家混合和视觉微调三种模型。
Phi-3.5系列的参数非常小,但性能却超过了Meta最新开源的Llama 3.1 8B和Mistral 7B等知名开源模型,也是目前开源大模型排行榜中唯一入选前10名的小参数模型。
所以,微软开源的Phi-3.5系列是专门面向那些算力、硬件有限的中小企业和个人开发者,同时可以部署在手机、平板电脑等移动设备中使用。
Mini开源地址:https://huggingface.co/microsoft/Phi-3.5-mini-instruct
专家混合:https://huggingface.co/microsoft/Phi-3.5-MoE-instruct
视觉:https://huggingface.co/microsoft/Phi-3.5-vision-instruct
微软其他模型开源地址:https://huggingface.co/microsoft
Phi-3.5架构简单介绍
Phi-3.5是2.0、3.0版本的延伸,使用的是Transformer解码器,有3072维隐藏层、32个注意力头以及32层架构。具有4K的默认上下文长度,并通过 LongRope扩展至128K,使得模型能够处理更长的文本序列,支持中文、英文、法文等。
此外,还使用了组查询注意力机制,每个注意力头的KV缓存中使用4个查询共享1个键。为了进一步提高训练和推理速度,微软使用了块稀疏注意力模块,能根据不同的稀疏模式有效地划分上下文,减少KV缓存的使用量。
Phi-3.5之所以能够实现如此出色的性能,主要原因之一是其使用了超过3.3万亿token高质量训练数据集。这个数据集是 phi-2 使用的数据集的扩展版本,由经过严格筛选的公开网络数据以及合成数据组成,在模型的预训练过程中发挥了巨大作用。
在安全优化方面,使用了监督微调、近端策略优化和直接偏好优化等方法,使Phi-3.5的输出更符合人类预期,极大减少非法、错误的内容输出。
三款模型
Phi-3.5-mini指令微调模型支持128K上下文,能生成文本/代码、数学推理、解读长文档、总结会议摘要等。在MMLU、MGSM、MEGA TyDi QA、MEGA XCOPA等测试基准中,整体性能超过Llama-3.1-8B、Mistral-7B。
Phi-3.5视觉模型除了文本生成之外,还支持图像识别、光学字符识别、图表/表格解读、图像比较、剪辑视频摘要等。
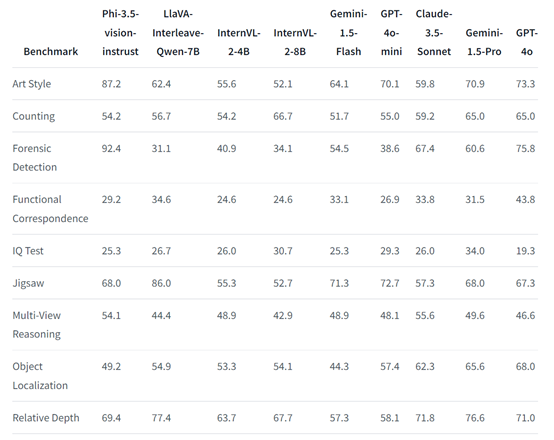
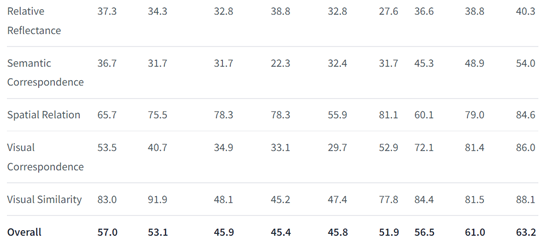
在Art Style、Counting、Forensic Detection、Jigsaw、Relative Depth、Visual Correspondence等视觉基准测试中,其性能超过了InternVL-2-4B/8B、GPT-4o-mini、Claude-3.5-Sonnet、Gemini-1.5-Flash等知名开闭源模型,仅次于GPT-4o。
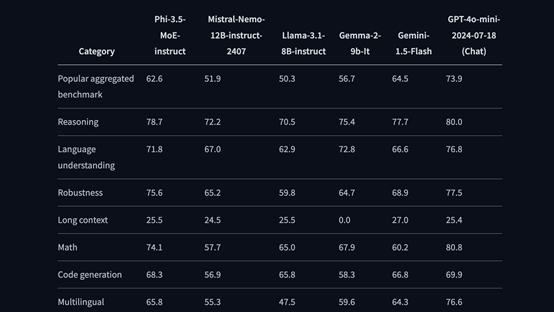
Phi-3.5专家混合模型共有420亿参数,但在推理的过程中只有66亿参数处于激活状态,其性能大幅度超过了同类开闭源模型,但对资源的消耗却非常低。
而专家混合模型可以根据不同场景的复杂任务,调动切换不同的专家模块来处理,进一步提升了对资源的合理分配。
专家混合模型之所以能够实现这种效率和性能的平衡,源于其独特的技术原理。在专家混合模型架构中,模型不是由单一的神经网络构成,而是由多个小型网络或专家组成。

每个专家负责处理其擅长的特定类型的任务。当模型接收到输入数据时,会通过 “门控网络”来决定哪些专家需要被激活,以及每个专家应该对最终的输出贡献多少。
专家混合模型的另一个技术优势是其可扩展性。随着开发人员对模型进行进一步的训练和优化,可以轻松地增加更多的专家来提升模型在特定领域的表现,或者通过改进门控网络来优化模型的决策过程。
本文素材来源微软,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



