谷歌通过数据增强、对比调优,减少多模态模型幻觉
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
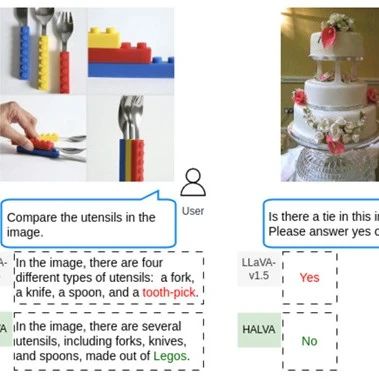
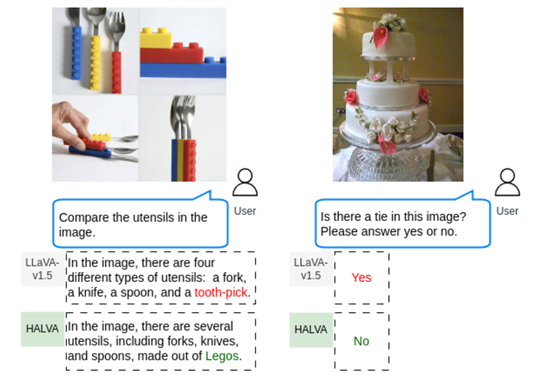
随着Gemini、GPT-4o等模型的出现,具备看、听、说的多模态大模型成为了新的主流。由于训练数据复杂、模型架构过于复杂,在生成、识别内容时很容易出现错误描述也称为“幻觉”,例如,当看到一张包含刀、叉和勺子的餐具图片时,模型会错误地描述为牙签。
为了解决这个难题,谷歌DeepMind、谷歌云AI研究、向量研究所和皇后大学的研究人员通过数据增强和对比调优的方法开发了HALVA模型。
论文地址:https://arxiv.org/abs/2405.18654
HALVA的核心思想是通过对比学习,来提高模型对真实和幻觉对象的区分能力。这种方法利用正确的对象描述和对应的幻觉描述来训练多模态模型,引导模型识别和生成与输入图像更加一致的描述。
首先,HALVA接收来自生成数据增强模块的输出,这些输出包括正确描述和幻觉化描述的对。这些成对的数据点是通过对原始图像进行智能的数据增强生成的,其中包括替换图像中的对象集合,引入了不存在的共现概念。例如,一个原本包含水果篮的图像可能会被增强为包含一个虚构的魔法球。
然后,HALVA将视觉-语言输入对送入预训练的多模态模型中。这些输入包括图像特征和相关的语言描述。多模态模型会对每个输入计算输出序列的概率分布,生成两组概率:一组对应于正确的描述,另一组对应幻觉错误的描述。
HALVA定义了一个对比损失函数,该函数基于正确描述和幻觉化描述的相对概率。损失函数的目标是最大化正确描述的概率,同时最小化幻觉化描述的概率。通过反向传播和梯度下降,模块优化损失函数,调整模型参数以减少幻觉描述的生成。

为了保证模型在调整过程中不会偏离其原始的预训练状态,对比调整模块引入了KL散度作为正则化项。这一步骤确保了模型在减轻幻觉化问题的同时,保持了其在一般视觉-语言任务上的性能。
在整个对比调整过程是端到端的,从输入的视觉-语言对到输出的损失函数,整个过程是连贯的,允许模型在训练过程中学习如何更好地区分真实和幻觉对象。
训练数据方面,HALVA是基于VG提供了丰富的视觉信息和语言描述,包含108K张图像及其详细注释的对象中心图像数据集。正确数据描述是Gemini Vision Pro通过 VG 数据集生成。

幻觉描述则比较麻烦一些,通过VG的封闭和开放两个数据集,封闭集是基于 VG 数据集中对象的已知共现关系来生成的,而开放集则是通过直接提示大语言模型来生成与原始对象共现的新对象。在生成了正确描述和幻觉描述的样本对之后,用于训练HALVA模型。
研究人员在CHAIR、MME – Hall、AMBER和 MMHal – Bench等平台中对HALVA进行了综合评估。结果显示,HALVA在减少模型幻觉方面非常出色,同时在一般视觉-语言任务上也表现出了良好的性能。
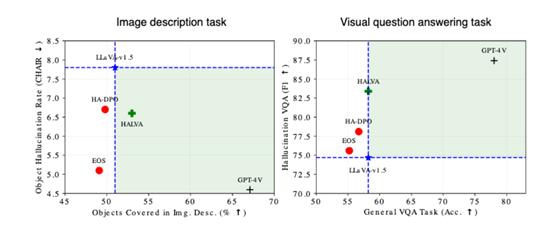
例如,在AMBER数据集上,HALVA在幻觉率指标上明显优于基础模型LLaVA-v1.5;在MMHal – Bench测试中,HALVA比基于RLHF、SFT 或 DPO的方法更有效地缓解了模型的幻觉问题。
本文素材来源HALVA论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



