英伟达开源新大模型:训练数据减少40倍,算力节省1.8倍
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
全球AI领导者英伟达(Nvidia)开源了最新大模型Nemotron-4-Minitron-4B和Nemotron-4-Minitron-8B。
据悉这两个模型是基于Meta开源的Llama-3.1 8B,但英伟达使用了两种高效的训练方法结构化剪枝和知识蒸馏。
相比从头训练,每个额外模型所需的训练token数据更少,仅需大约1000亿token,最多减少40倍,算力成本可节省1.8倍。性能却依然媲美Llama-3.1 8B、Mistral 7B、Gemma 7B等知名模型,而这些模型是在高达15万亿token数据训练而成。
4B开源地址:https://huggingface.co/nvidia/Nemotron-4-Minitron-4B-Base
8B开源地址:https://huggingface.co/nvidia/Nemotron-4-Minitron-8B-Base

结构化剪枝方法
剪枝作为一种大模型压缩技术,其核心思想是去除神经网络中不重要的权重。在大模型中,每个神经元通过一系列权重与其他神经元相连,这些权重决定了信号在网络中的传递强度。通过移除那些对模型输出影响较小的权重,从而减少模型的复杂性和计算需求。
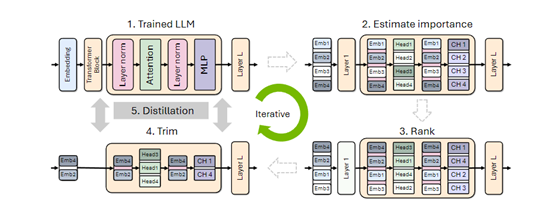
传统的剪枝方法是随机或根据特定策略移除权重矩阵中的单个元素。虽然这种方法能有效减小模型的体积,但对硬件的利用效率不高,因为它破坏了权重矩阵的结构,难以充分利用现代硬件的并行计算优势。
所以,英伟达使用了一种结构化剪枝方法,保留了权重矩阵的结构,通过移除整个神经元、注意力头或卷积滤波器等,使得剪枝后的模型仍然适合在GPU、TPU等硬件上高效运行。这不仅降低模型的内存占用和计算需求,还可能提升模型的训练速度和推理时间,使得大模型可以在有限的资源环境中进行部署。
在实际应用中,剪枝策略的选择依赖于模型的具体结构和优化目标。例如,剪枝神经元意味着减小神经网络层的宽度,剪枝注意力头则影响模型对输入序列的理解方式,而剪枝模型的深度则直接减少模型的层数。
英伟达的研究人员在剪枝的过程中发现,在不同的剪枝轴上,比如宽度和深度,采用不同的策略会产生不同的效果。
初期单独剪枝神经元和注意力头比同时剪枝神经元、注意力头和嵌入通道更有效,但经过几次迭代的重新训练后,这种顺序可能会发生变化。而宽度剪枝在重新训练后通常比深度剪枝有更好的效果。
知识蒸馏
使用剪枝后的模型通常需要一个重新训练的阶段以恢复和优化性能,知识蒸馏便是最佳方法之一。
其原理非常简单,就是让剪枝后的“学生模型”来模仿未剪枝的“教师模型”的行为,可以在使用极少量原始训练数据的情况下,显著提升剪枝模型的表现。

尤其是,当大模型的深度被大幅减少时,使用logit、中间状态和嵌入的蒸馏策略更为有效;而当深度变化不大时,仅使用logit蒸馏就足够了。
英伟达在训练Nemotron-4-Minitron-4B和Nemotron-4-Minitron-8B时,使用的便是基于logit的知识蒸馏方法,让学生模型的输出概率分布模仿教师模型,从而学习到教师模型对数据的深层理解。
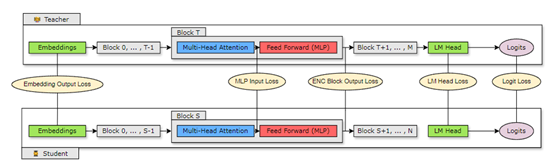
作为softmax层之前的输出,logits代表了模型对每个词汇的原始预测分数。通过最小化学生模型和教师模型logits之间的差异,学生模型能够学习到教师模型的软概率分布,而不仅仅是最终的预测结果,这增加了学生模型泛化能力的信息量。
除了logits层面的蒸馏,英伟达还探索了中间层特征的蒸馏,通过将教师模型的隐藏层状态映射到学生模型,并最小化这些状态之间的差异,进一步提高了学生模型的性能。这种方法使学生模型能够学习到教师模型在不同层次上的表示能力,更好地捕捉数据的复杂特征。
在损失函数的选择上,尝试了多种损失函数,包括Kullback-Leibler散度、均方误差和余弦相似度等。他们发现,对于深度减少的学生模型,使用logits损失和中间层损失的组合可以取得更好的效果。
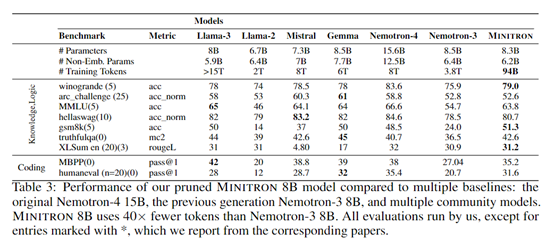
根据测试数据显示,经过结构化剪枝和知识蒸馏的Minitron-4B和Minitron-8B模型,与从头训练模型相比训练数据减少了40倍,算力需求节省1.8倍,在MMLU上的评分提升16%,性能可媲美Mistral 7B、Gemma 7B和Llama-3 8B。
本文素材来源英伟达官网,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



