LG开源韩语大模型Exaone 3.0,8万亿token训练数据
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
LG的AI研究机构开源了首个开放权重的大模型——EXAONE 3.0。
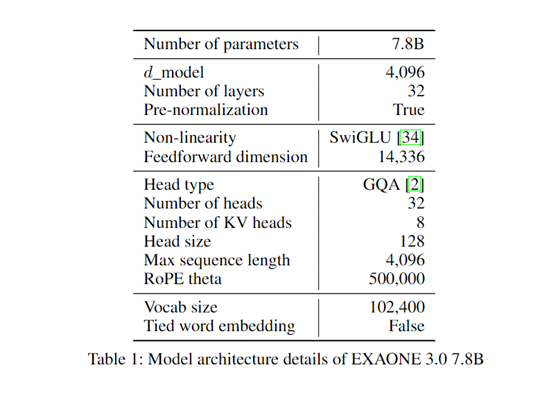
EXAONE 3.0是一个指令微调模型有78亿参数,经过了8万亿token高质量数据进行了综合训练。支持韩语和英文两种语言,尤其是对韩语的支持非常出色。
在KMMLU、KoBEST – BoolQ、KoBEST – COPA等基准测试中,高于Llama 3.1-8B、Gemma 2-9B等知名开源模型。
开源地址:https://huggingface.co/LGAI-EXAONE/EXAONE-3.0-7.8B-Instruct
论文地址:https://arxiv.org/abs/2408.03541

EXAONE 3.0使用了目前主流的解码器仅变换器架构,与传统变换器相比,摒弃了编码器部分,专注于通过解码器生成输出序列,减少了模型的复杂性,同时提高了处理长距离依赖关系的能力。
在上下文长度方面,EXAONE 3.0支持4,096 token,使得模型能够同时处理和记忆高达4,096个连续token的信息,极大地增强了其在理解语言连贯性方面的能力,在生成文本、翻译、摘要等提供了更好的生成、解读能力。

EXAONE 3.0还使用了RoPE和GQA来提升对长序列数据的处理能力。RoPE能够有效地编码位置信息,帮助模型理解文本中单词的顺序关系,对于处理长文本序列非常重要。而GQA则有助于提高模型对不同查询的关注能力,使其能够更准确地聚焦于关键信息,从而提升模型的性能。
为了更好地处理韩语数据,研究人员使用MeCab对韩语语料进行预标记,然后从零开始训练BBPE标记器,词汇量为102400。与其他标记器相比,这种设计在英语上实现了相似的压缩比,但在韩语上的压缩比更低。
压缩比越低意味着标记器为每个单词生成的标记更少,这有助于避免过度标记化的问题。对于韩语这种具有粘着结构的语言来说,单词可以通过组合多个词素形成,减少标记数量可以更好地保留语言的结构和语义信息。
EXAONE 3.0的预训练一共包含两个阶段:第一阶段使用了6万亿token的数据,以优化在一般领域的能力表现;第二阶段,进一步接受了额外2万亿token的训练,重点放在提高语言技巧和专业知识上。
为了达到这一目标,研究团队重新平衡了数据分布,增加专家领域数据的比例,并通过创建分类器来评估数据质量,确保高价值数据的有效利用。

在优化阶段,为了增强EXAONE 3.0 模型的指令跟随能力,LG的研究人员使用了SFT(监督微调)和DPO(直接偏好优化)。
SFT阶段涉及创建高质量的指令调优数据,通过定义广泛的服务导向指令和话题,制作出能够模拟真实用户交互的多轮对话数据集。

在DPO优化阶段,模型通过人类反馈进行调整,以最大化在偏好数据集中选定和拒绝响应之间的奖励差异,这一过程包括离线DPO和在线DPO两个步骤,前者利用预构建的偏好数据进行模型训练,后者则通过动态配置与离线学习数据分布相似的提示,持续优化模型性能。
为了评估EXAONE 3.0的性能,研究人员在MT-Bench、Arena-Hard-v0.1、WildBench和AlpacaEval 2.0 LC等基准平台进行了综合测试。

结果显示,EXAONE 3.0在韩语和英语双测试中,其数学、编码、推理等能力,超过了Llama 3.1 8B、Gemma 2 9B、Phi 3 7B等知名模型。如果你想开发专门用于韩语的类ChatGPT生成式AI应用,使用Exaone 3.0是一个不错的选择。
本文素材来源EXAONE 3.0论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



