TII开源第一个纯Mamba架构大模型,超过Llam3.1
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
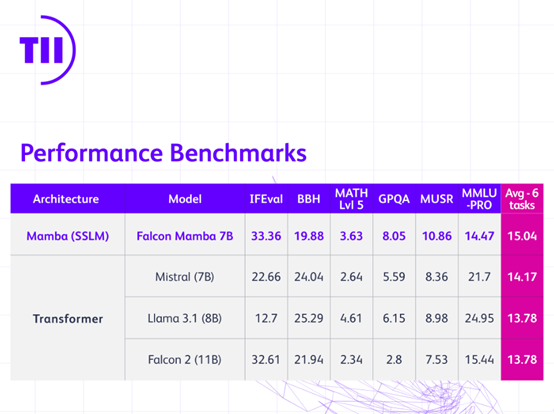
阿联酋技术创新研究(简称“TII”)开源了全球第一个纯Mamba架构的大模型——Falcon Mamba 7B。
根据评测数据显示,Falcon Mamba 7B的性能已经超过了Meta最新开源的Llama 3.1-8B、Mistral-7B等知名开源模型。
开源地址:https://huggingface.co/tiiuae/falcon-mamba-7b
在处理序列时,传统的Transformer模型在生成下一个令牌时需要关注上下文中所有先前的令牌的键和值,这导致内存需求和生成时间随着上下文长度的增加而线性增长。
而像Falcon Mamba这样的状态空间语言模型,只关注和存储其循环状态,因此在生成大序列时不需要额外的内存或时间在处理长序列方面拥有很强的技术优势。
Mamba模型采用了编码器-解码器结构,编码器负责处理输入的文本,而解码器则生成输出文本。这种结构特别适合文本生成任务,因为它能够有效地将输入信息转化为流畅的输出文本。此外,Mamba模型还使用了多头注意力技术,使得它能够同时关注输入序列的不同部分,捕捉不同层次的信息。

为了保持序列中的顺序信息,Mamba模型在输入数据中加入了位置编码,这样模型就可以识别每个单词在序列中的具体位置。在每个子层之后,模型还会应用层标准化技术,有助于稳定训练过程,防止梯度消失或爆炸的问题。残差连接的使用进一步提高了模型在处理深层网络时的信息传播效率,缓解了梯度消失的问题。
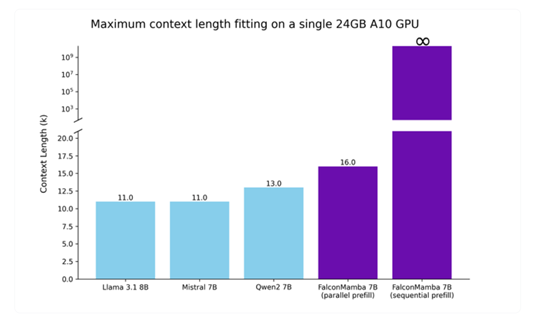
此外,Falcon Mamba的训练效率非常高,针对特定硬件进行了优化,例如,在单个A10 24GB GPU上就能轻松运行。
训练数据方面,Falcon Mamba – 7B使用了大约5500GT的数据量,包含了RefinedWeb等从互联网上精心筛选和提炼出来的数据集。
在训练过程中,模型大部分时间采用的是恒定学习率,这有助于模型在初期快速学习并捕捉数据中的关键特征。随后,训练进入了相对较短的学习率衰减阶段,这一阶段的目的是微调模型的参数,以提高其在细节上的准确性和性能。
本文素材来源TII官网,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



