斯坦福、Salesforce等开源1万亿tokens多模态数据集
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
华盛顿大学、斯坦福大学、Salesforce等研究人员联合开源了多模态数据集MINT-1T。
据悉,MINT-1T共包含了大约1万亿个文本标记和34亿张图像,是现有开源多模态数据集的10倍,同时还首次从ArXiv网站中爬取了专业论文,进一步提升了数据质量。这对于开源领域开发GPT-4o、Gemini等多模态模型,提供了全面、多元化的数据集。
开源地址:https://github.com/mlfoundations/MINT-1T
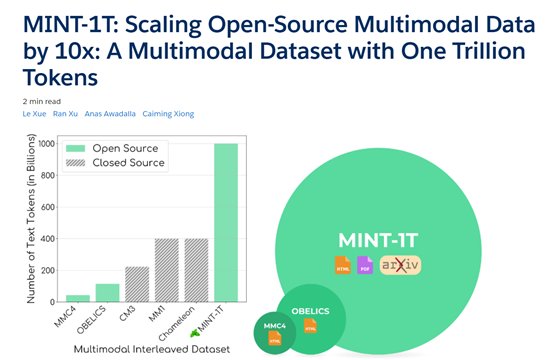
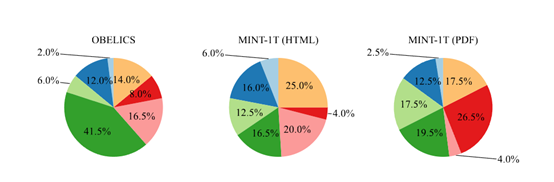
MINT-1T数据集包含了多种来源,其中,HTML文档的主要来源于CommonCrawl,是一个非盈利性的组织,通过爬取互联网上的网页生成了大量的数据集,被广泛用于各种学术研究和模型训练。
在提取的过程中,为了确保数据集的质量和多样性,研究人员对文档进行了数据过滤,排除了那些不包含图像或包含超过三十张图像的文档,同时剔除了那些图像URL中包含不适当子字符串(例如,logo、avatar、porn、xxx等)的文档。
在处理HTML文档时,团队采用了OBELICS的方法,通过解析WARC条目的DOM树来提取交错的多模态文档。这种方法允许团队在保持图像和文本原始顺序的同时,提取出有用的数据。

此外,团队还对HTML文档进行了去重处理,使用了Bloom Filter技术,通过设置0.01的误报率,对13-gram段落进行去重。如果一个文档中超过80%的段落是重复的,那么整个文档就会被丢弃。这种方法有效地减少了数据集中的冗余内容,提高了数据的质量和可用性。
PDF文档是MINT-1T数据集中的另一个重要组成部分。这些文档主要来源于CommonCrawl WAT文件,涵盖了2023年2月——2024年4月的数据。与HTML文档的处理方法类似,研究人员首先从这些转储中提取所有PDF链接,然后尝试使用PyMuPDF 2下载和读取PDF文件。
在处理的过程中,研究人员对PDF文件的大小和页数进行了限制,排除了超过50MB大或超过50页的PDF文档。这是因为这些文档通常包含大量的图像,可能会影响数据处理的效率和效果。

ArXiv是全球著名提供物理、数学、计算机科学、AI等领域的专业论文网站,研究人员从这里提取了大量基于LaTeX源代码的文档,包含了论文的文本内容、图像、表格、参考文献等所有元素。
在处理LaTeX源代码时首先需要识别图形标签,这些标签通常以includegraphics的形式出现,指示了图像在文档中的位置。
通过分析这些标签,研究人员能够确定图像在文本中的相对位置,并据此将图像与文本内容进行交错,这对于保持文档的原始结构和阅读顺序至关重要。
在获取了经过初步处理的PDF、HTML等数据后,研究人员对这些数据做了进一步处理。首先,使用Fasttext的语言识别模型排除了非英语文档,以确保数据集的语言一致性。
其次,删除了URL包含NSFW子字符串的文档,以排除色情和不良内容。还使用了RefinedWeb的文本过滤方法,移除了包含过多重复n-gram或被识别为低质量的文档。
在图像过滤方面,团队尝试下载HTML数据集中的所有图像URL,丢弃了任何无法检索的链接,并移除了没有有效图像链接的文档。为了提高图像质量,移除了小于150像素的图像,以避免包含诸如徽标和图标等噪声图像。
为了确保数据集的安全性和合规性,研究人员对所有图像使用了NSFW图像检测器。如果发现文档包含单个NSFW图像,则丢弃整个文档。同时对对文本数据中的电子邮件地址和IP地址等个人信息,进行了匿名化处理防止敏感数据泄露。
本文素材来源MINT-1T论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



