Contextual AI获8000万美元,为大模型提供RAG 2.0
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
Contextual AI在官网宣布获得8000万美元A轮融资,本次由Greycroft、Bain Capital Ventures、英伟达、汇丰创投、光速资本等投资。
Contextual AI创立于2023年,其联合创始人兼首席执行官Douwe Kiela曾在微软研究院、Meta、Hugging Face担任AI研究员,主攻方向就是RAG(知识检索增强)同时也是该领域的先驱之一。
RAG是一种创新的技术框架,旨在增强大模型处理知识密集型任务的能力。在生成式AI领域,模型受限于在训练过程中所接触到的信息量,即使是最先进的大型语言模型,例如,GPT-4,也可能在面对特定领域或实时数据查询时显得力不从心,因为它们的训练数据是有限的。

为了解决这一问题,Douwe Kiela提出了RAG的概念,核心思想是将大模型与一个检索器结合,后者可以访问外部数据源,例如,维基百科、谷歌搜索等,以补充模型固有知识。
当模型再遇到需要外部信息的问题时,检索器就能查找相关的资料,然后语言模型利用这些资料生成更加准确和全面的回答。
但是传统的RAG存在一些关键性的缺陷,由冻结模型、矢量数据库和黑盒语言模型组成,这些组件被机械地拼接在一起,缺乏统一的训练和优化过程。
因此,在今年的3月19日,Contextual AI提出了RAG 2.0版本,将语言模型和检索器作为一个单一的集成系统进行训练。这意味着RAG 2.0不仅能从头开始预训练模型,还能针对特定任务进行微调,同时确保检索器和语言模型之间的无缝协作,以最大化整体性能。
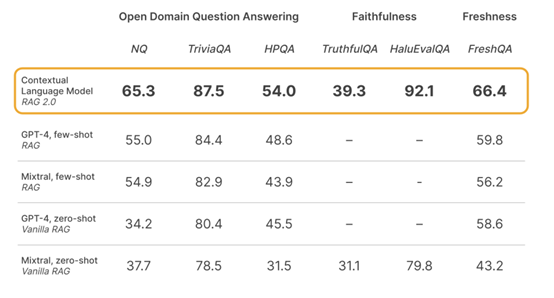
为了验证RAG 2.0的优越性,Contextual AI进行了多个关键领域,包括开放域问答、忠实度和新鲜度等广泛的基准测试,比较了其Contextual Language Models与基于GPT-4和其他最先进的开源模型构建的冻结RAG。
在开放域问答方面,使用了Natural Questions(NQ)、TriviaQA和HotpotQA等数据集来评估模型检索相关知识并准确生成答案的能力。
忠实度测试则通过HaluEvalQA和TruthfulQA衡量模型是否能够基于检索到的证据生成回答而不产生幻觉。此外,还评估了各RAG对快速变化的世界知识的泛化能力,使用了最新的FreshQA基准。
在真实世界的数据应用上,显示出了比当前方法更大的优势,尤其是在金融、法律和硬件工程等专业领域。
综合测试结果显示,Contextual AI提出的RAG 2.0性能比GPT-4、Mixtral开闭源模型更好。
本文素材来源Contextual AI官网,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



