杀疯了!Meta开源SAM-2:可商用,随意分割视频、图像
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
2023年4月5日,Meta首次开源了视觉分割模型SAM,能够根据交互和自动化两种方式任意切割视频、图像中的所有元素,当时这个模型被誉为计算机视觉界的“ChatGPT时刻”。目前,SAM在Github超过45000颗星。
今天凌晨,Meta在SAM的基础之上对架构、功能以及准确率等进行大量更新,正式开源了SAM-2,并支持Apache 2.0规则的商业化。这也是继上周Llama 3.1之后,再次开源重磅模型。
同时Meta还分享了SAM-2的训练数据集SA-V,包含了51,000真实世界视频和超过600,000个时空遮罩,这比其他同类数据集大50倍左右,可帮助开发人员构建更好的视觉模型。
SAM-2开源地址:https://github.com/facebookresearch/segment-anything-2
在线demo:https://sam2.metademolab.com/
数据集地址:https://ai.meta.com/datasets/segment-anything-video/

SAM-2架构简单介绍
SAM-2基础架构是基于transformer模型并引入了流式记忆机制,主要由图像编码器、记忆编码器、记忆注意力模块、提示编码器和掩模解码器等模块组成。
图像编码器作为SAM-2处理视频帧的起点采用了流式处理方法,能够处理任意长度的视频,相比第一代可以使用更少的交互提升3倍效率。它使用的是一个预训练的Hiera模型,能够提供多尺度的特征表示,为后续的记忆注意力模块和掩模解码器提供丰富的上下文信息。
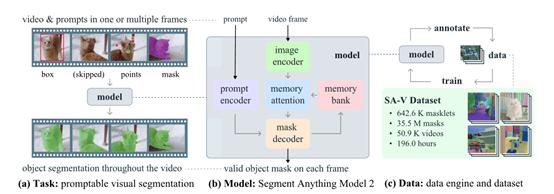
记忆编码器和记忆注意力模块是本次SAM-2的重要创新之一。记忆编码器负责将模型先前的预测和用户交互动作编码为记忆,并将这些记忆存储在记忆库中,用于影响后续帧的分割结果。
记忆注意力模块则利用这些记忆来增强当前帧的特征表示,使其能够更好地捕捉目标对象在时间序列中的动态变化。
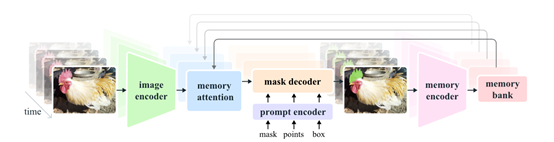
记忆编码器通过将预测的分割掩模降采样并与当前帧的特征融合,生成记忆特征。随后通过一系列轻量级的卷积层进一步处理,以整合信息。记忆库则保留了目标对象在视频中的历史信息,通过维护一个先进先出队列来存储最近N帧的记忆。
提示编码器的设计遵循了SAM的原则,能够接受点击、框选或遮罩等不同类型的提示,以定义给定帧中对象的范围。这些稀疏提示通过位置编码和学习到的嵌入表示进行表示,而遮罩则通过卷积操作进行嵌入,并与帧嵌入相加。
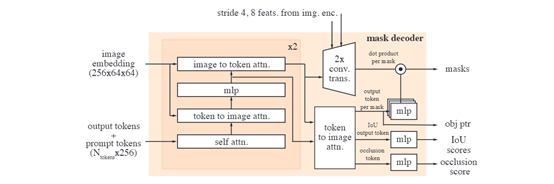
掩模解码器的设计在很大程度上遵循了第一代SAM的架构,使用了双向transformer块,这些块更新提示和帧嵌入。为了处理可能存在多个兼容目标掩模的模糊提示,SAM-2预测每个帧上的多个掩模,这对于确保模型输出有效掩模至关重要。
SA – V训练数据集
现有的视频分割数据集通常存在一些限制,例如,注释对象主要集中在人、车辆和动物等特定类别,并且往往只覆盖整个对象而忽略了部分和子部分。
此外,这些数据集的规模相对较小,无法满足训练强大的视频分割模型的需求。为了解决这些难题,Meta开发了SA – V数据集并使用了三大阶段。
在第一阶段,使用了SAM模型来辅助人类标注。标注者的任务是在视频的每帧中以每秒6帧的速度使用SAM和像素精确的手动编辑工具来标注目标对象的掩码。
由于这是一种逐帧的方法,所有帧都需要从头开始标注掩码,因此流程非常缓慢,平均标注时间为每帧37.8秒。但这种方法能够产生高质量的空间标注,在这个阶段,共收集了16000个掩码片段,涵盖了1400个视频。
第二阶段,引入了SAM 2 Mask,它只接受掩码作为提示。标注者首先使用SAM和其他工具在第一帧中生成空间掩码,然后使用SAM 2 Mask将标注的掩码在时间上传播到其他帧,以获得完整的时空掩码片段。
通过这个阶段的工作,收集了635,000个掩码片段,标注时间下降到每帧7.4秒,相比第一阶段有了显著的提高,速度提升了约5.1倍。
第三阶段,使用了完全功能的SAM-2,它能够接受各种类型的提示,包括点和掩码。与前两个阶段不同,SAM-2受益于对象在时间维度上的记忆来生成掩码预测。
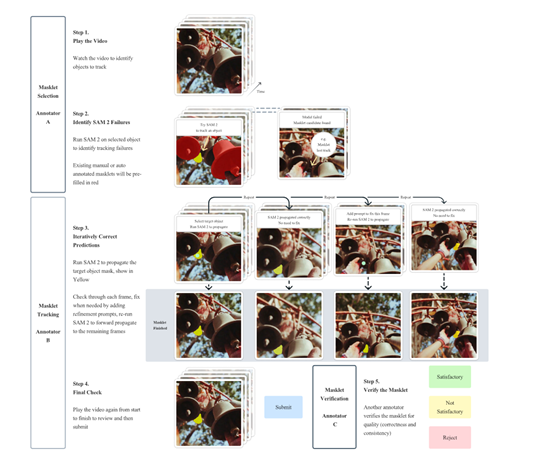
这意味着标注者只需要偶尔对SAM 2提供的预测掩码进行细化点击,就能够在中间帧中编辑预测的掩码片段,而不需要像在第一阶段那样从头开始标注。通过多次重新训练和更新SAM-2,标注时间进一步下降到每帧4.5秒,相比第一阶段速度提升了约8.4倍。
所以,SA – V在开发SAM-2过程中发挥了重要作用,也是目前最大视觉分割训练数据集之一。
本文素材来源SAM-2论文、Meta官网,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



