开源视频模型SV4D,一键创建8角度动态3D视频
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
Stability.ai开源了创新视频模型Stable Video 4D(简称“SV4D”),可将一个视频轻松创建8个角度的动态3D视频。
使用方法也非常简单,用户只需要上传视频然后选择3D 相机姿势,经过大约40秒左右的推理就能完成视频创建。相比SV3D、STAG4D等同类模型,SV4D的推理效率和生成质量都获得了大幅度提升。
开源地址:https://huggingface.co/stabilityai/sv4d

以目前的技术,用单个视频生成动态3D视频面临不少难题。因为这涉及同时推理对象在未见过的相机视角下的外观和运动,同时对单个给定视频可能有多种合理的动态解释进一步加大了生成难度。
此外,训练一个能推广到不同对象类型和运动的强大生成模型面临两大技术挑战:1)缺乏大规模的动态3D对象数据集来训练稳健的生成模型;2)问题的高维性质需要大量参数来表示对象的3D形状、外观和运动。
而SV4D与以往生成模型不同的是,以一个统一的扩散模型作为基础,能够同时处理视频帧和视角的生成。这种架构解决了之前需要分别训练视频生成和新视角合成的模型,效率低下的问题,而且还保证生成内容的一致性。
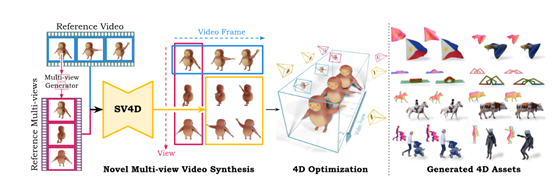
在技术实现上,SV4D使用了Stability.ai之前开源的SVD和SV3D网络结构,融合了视频和多视角扩散模型的优势。这个网络结构包含一个多层的UNet,每层由一个残差块和三个带有注意力层的transformer块组成。
这些注意力层包括空间注意力、视角注意力和帧注意力,协同生成以确保生成的视频在空间和时间上都具有高度的一致性。
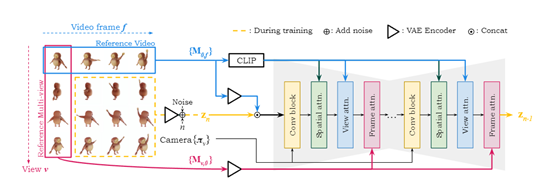
视角注意力的设计是为了对每个视频帧中的多视角图像进行对齐,以参考视频中的第一视角为条件。这种设计允许模型在生成新视角时,能够保持与原始视角的一致性,从而确保了多视角视频的连贯性。
帧注意力则进一步确保了视频在时间维度上的连贯性,通过对每个视角的多帧图像进行对齐,以每个视角的第一帧为条件,模型能够生成在时间上连续且一致的视频序列。
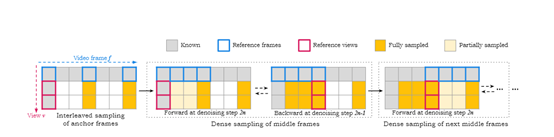
在模型训练阶段,SV4D面临的一个关键难题是需要同时生成V×F的图像网格,对于较长的输入视频算力会呈指数级增长。为了解决这个问题,研究人员通过顺序处理交错的输入帧子集,同时保持输出图像网格的一致性。
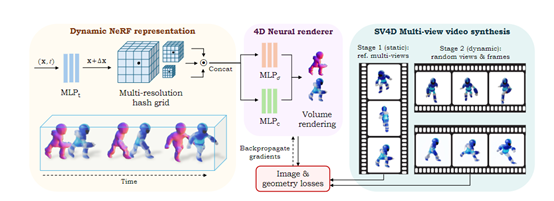
在训练数据方面,由于目前还没有大规模的动态3D对象训练数据集,研究人员就从现有的Objaverse数据集中精心整理了一个新训练数据集ObjaverseDy。
在整理数据集时,进行大量数据筛选然后去除动画帧数过少的对象。为了进一步过滤出运动极小的对象,研究人员对每个视频的关键帧进行子采样,并对这些帧之间的最大L1距离应用简单阈值作为运动测量。在渲染训练新视角视频时,可灵活选择相机与对象的距离,并动态调整时间采样步骤,以确保获得高质量的动态3D对象集合和渲染的多视角视频。
为了评估SV4D的性能,研究人员在ObjaverseDy、Consistent4D和真实世界视频数据集DAVIS等进行了综合测试,并与其他先进模型进行了比较。
在Consistent4D数据集上,SV4D在视频帧一致性方面表现出色,同时保持了与其他方法相当的图像质量。与SV3D和STAG4D相比,FVD – F分别降低了31.5%和21.4%。
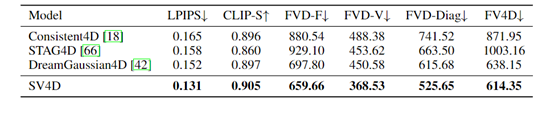
在Objaverse数据集上,SV4D在视频帧一致性和多视角一致性方面都有显著优势,FVD – F更低,FVD – V更好,在FVD – Diag和FV4D方面也超过了先前的先进方法,证明合成的新视角视频在视频帧和多视角一致性方面更好。
END



本篇文章来源于微信公众号: AIGC开放社区



