提升5.69倍,高效RAG上下文压缩方法COCOM
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
GPT-4、Llama等开闭大模型通过预训练的方式将海量数据积累成一个庞大的知识库,再通过文本问答的形式为用户生成各种内容。但这种方法仅局限于训练数据集,为了扩大输出范围允许模型通过检索额外的数据来丰富生成内容,RAG(知识检索增强)成为了必备功能之一。
RAG也有一个明显的缺点,就是随着上下文信息量的增加,模型的解码时间显著延长,严重影响用户获取答案的效率。
所以,阿姆斯特丹大学、昆士兰大学和NAVER实验室的研究人员联合发布了创新压缩方法COCOM(Context COmpression Model)。
论文地址:https://arxiv.org/abs/2407.09252

在传统的RAG模型中,为了生成一个准确的答案,系统需要考虑大量的上下文信息。这些信息可能来自多个文档,每个文档都包含了对生成答案可能有用的信息。
不过将这些长文本直接输入到大模型中会导致解码时间显著增加,因为模型需要处理更多的输入数据,消耗的算力和推理时间也就更多。
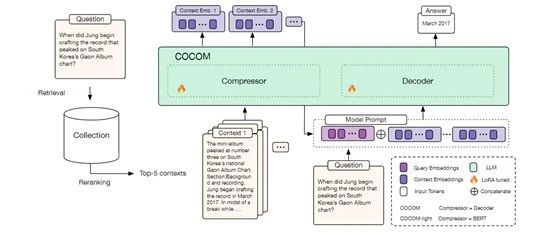
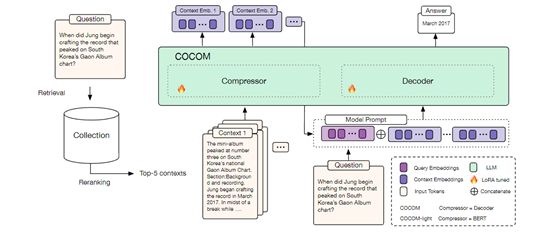
COCOM使用了一种创新的上下文压缩技术,将长文本上下文转换成一组紧凑的上下文嵌入。这些嵌入能够捕捉原始文本的关键信息,并以一种更高效的方式提供给大模型,能够在减少模型输入大小的同时,保持提升生成内容的质量。
COCOM还使用了一个转换器,帮助大模型对输入的上下文进行分词处理,将其转换成一系列的标记。然后,这些标记被输入到一个压缩模型中,并负责将这些标记转换成一组上下文嵌入。
在压缩模型的训练过程中,研究者们采用了两种主要的预训练任务:自编码和基于上下文嵌入的语言建模。自编码任务的目标是训练模型将上下文嵌入重构回原始的输入文本,这有助于模型学习如何有效地压缩和解压上下文信息。
而基于上下文嵌入的语言建模任务则是训练模型根据压缩后的嵌入生成文本的下一部分,这有助于模型学习如何利用上下文嵌入中的信息。
值得一提的是,COCOM的压缩率非常灵活可以调节,通过调整压缩率参数帮助开发人员在减少解码时间和保持答案质量之间找到一个平衡点。
例如,一个较低的压缩率可能会生成更多的嵌入,从而保留更多的上下文信息,但同时也会略微增加解码时间。相反,一个较高的压缩率会减少生成的嵌入数量,从而加快解码效率,但可能会牺牲一些生成答案的质量。
此外,COCOM还能够处理多个上下文的情况。在知识密集型任务中,通常需要从多个文档中提取信息以生成答案。COCOM能够独立地压缩每个文档的上下文,并将生成的嵌入向量作为一组提供给大模型,这种方法能帮助模型在处理多个上下文时仍保持高效率。
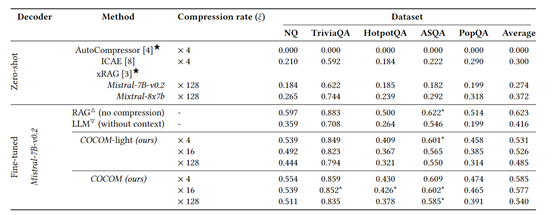
研究人员在Natural Questions、MS MARCO、HotpotQA测试平台中评估了COCOM,并与现有AutoCompressor、xRAG、ICAE等压缩方法进行比较,COCOM的效率能提升5.69倍,内存减少1.27倍。
本文素材来源COCOM论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



