基于Mamba架构的,状态空间音频分类模型AUM
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
Transformer凭借强大的自注意力机制,成为文本、音频、视频等模型的基础架构之一。但其计算复杂度随着序列长度的增加而呈指数级增长,这在处理长序列数据时会出现严重的效率问题。
韩国高等科学技术院的研究人员受最新的Mamba架构启发,开发了首个没有自注意力机制纯粹状态空间的音频分类模型Audio Mamba(下面简称“AUM”)。
状态空间是Mamba架构的核心功能之一,这是一种用于描述和预测系统状态随时间变化的数学模型,通过维护一个隐藏状态来映射输入序列到输出,可帮助模型能够以线性时间复杂度高效处理数据,无论序列多长都没有问题。
论文地址:https://arxiv.org/abs/2406.03344

AUM架构简单介绍
在AUM架构中,先通过傅里叶变换方法,将原始的音频波形首先被转换成频谱图。把得到的频谱图随后被划分成一系列规则的 “patches”块。每个patch都是一个正方形矩阵,代表了音频信号的一个局部特征区域。通过这种方式,将音频信号被分解为一系列的局部特征,为后续的数据处理奠定了基础。
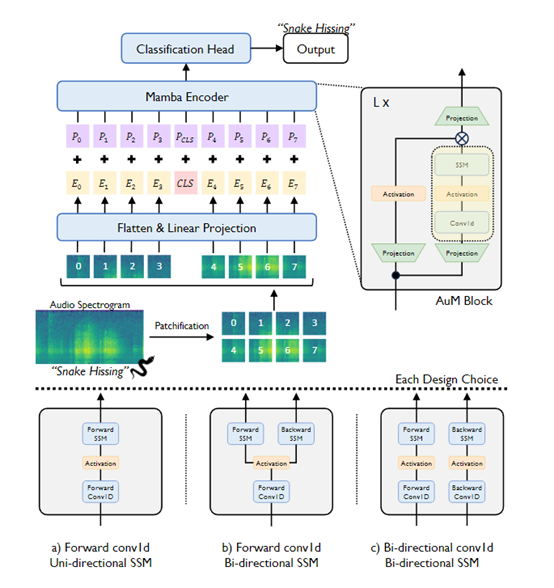
接着,每个patch通过一个线性投影层被嵌入到一个高维空间中。在这个嵌入过程不仅将原始的音频特征转换为模型可以处理的形式,而且还通过引入一个特殊的分类标记来增强模型的分类能力。
这个分类标记被放置在嵌入序列的中间位置,将作为模型训练和推理过程中的关键元素,帮助模型集中注意力于音频数据中最重要的部分。
再从序列的末尾开始,通过反向卷积层和状态空间模型来提取特征,帮助AUM模型能从不同的角度理解音频数据,增强了模型对音频信号全局上下文的理解能力。
此外,AUM还采用了一种现代化的硬件优化扫描方法,能够从输入序列的开始到结束进行单向扫描,同时更新模型的隐藏状态。不仅提高了模型的处理效率,还使得模型能够选择性地更新其隐藏状态,从而更有效地捕捉输入序列中的相关信息。
实验测试与数据集
为了测试AUM的性能,研究人员使用了AudioSet、VGGSound、VoxCeleb、Speech Commands V2和EPIC-SOUNDS等多个知名音频数据集进行了综合评估。
这些数据集不仅在规模上有所不同,在音频样本的多样性和复杂性上也各有特点。例如,AudioSet数据集包含了超过200万个10秒长的音频剪辑,涵盖了527个不同的标签;而VGGSound则包含了近20万个视频剪辑,每个剪辑都有10秒长,标注了309种不同的声音类别。

结果显示,AuM在AudioSet上的平均精准度达到了32.43%,比知名的Audio Spectrogram Transformers(简称“AST”)模型高出3.33%;在VGGSound上,准确率提高到42.58%,比AST提升了5.33%。
在VoxCeleb、Epic-Sounds和Speech Commands V2,AuM也显示出了卓越的数据序列处理性能。

除了性能优秀,AuM对计算效率和内存消耗也比AST强很多。在处理长序列音频数据时,AuM显示出了显著的内存效率,这得益于其基于状态空间模型的架构,能够在保持性能的同时减少内存使用。
此外,AuM在推理阶段的效率也比AST快,这意味着在实际应用中,AuM能够提供更快的推理响应,对于需要实时音频处理的业务场景尤为重要。
本文素材来源AuM论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



