Meta发布混合多模态模型—Chameleon
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
全球科技、社交巨头Meta发布了混合多模态模型Chameleon,一共有7B和34B两个版本。
Chameleon可以生成、处理混合多类型内容,包括文本、图片、图像字幕等。同时可以自动生成带图文的长篇内容,整体性能非常强劲。
根据多平台测试数据显示,Chameleon的性能超过了谷歌的Gemini Pro和OpenAI的GPT-4V等知名多模态模型。
论文地址:https://arxiv.org/abs/2405.09818

传统的多模态大模型使用的分阶段处理策略,先分开独立处理图像和文本,然后在后续阶段将这些模态数据融合。这种方法虽然简单直观,却难以高效地捕捉和利用跨模态的复杂关联。
而Chameleon使用了一种创新处理方法,从一开始便将所有模态信息投影到一个共享的表示空间中。图像和文本数据被同等对待,共同参与模型的输入和处理过程,从而打破了模态之间的界限。
Chameleon的技术创新在于使用了一种“全tokens化”的表示方法将图像也转换成离散的tokens,使得图像和文本可以使用同一套Transformer架构进行处理。
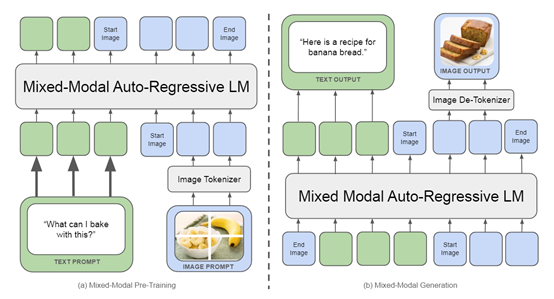
这不仅简化了模型架构,还促进了模态间的语义对齐。通过将图像分割成像素块并对其进行量化,Chameleon能确保每个图像tokens都能携带视觉特征的重要信息,就像文本tokens携带语义信息一样,无论是文本还是图像,都被转化为模型能够理解和操作的统一语言。
Chameleon的训练分为两个阶段:初步的80%训练专注于基础的多模态理解,而后20%的训练则着重于提升模型的综合能力。
在第一阶段,模型接触到的训练数据包括大量的无监督文本、文本-图像对以及交错的文本/图像数据,该数据来源于公共网络资源和授权数据集,经过精心处理以适应模型的需求;
第二阶段则进一步强化模型的多任务处理能力,确保其在面对具体应用时表现更为出色。
此外,Chameleon还使用了一个非常庞大的训练数据集,包括文本、代码、视觉聊天、图像生成、交错文本/图像生成以及安全数据,确保了模型能够应对多样化的应用场景。
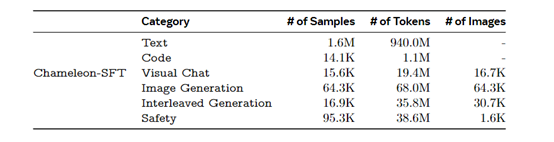
其文本和代码相关的数据集分别继承自LLaMa-2和CodeLLaMa的预训练数据。在图像生成数据集中,研究人员精心筛选了图像,并通过特定的美学分类器进行分类,最终保留了接近512×512分辨率的高质量图片,以匹配图像tokens化的原生需求。
在推理阶段,Chameleon展示了其对混合模态生成的独特处理方式。模型能够处理数据依赖性、模态约束生成和固定大小的文本单元等挑战。

Chameleon的推理策略包括对生成流程的优化,以提高吞吐量并减少延迟。这种优化是通过一个基于PyTorch的独立推理管道来实现,该管道利用了xformers库中的GPU内核。
研究人员将Chameleon在多个知名测试平台与市面上的主流多模态模型进行了对比。结果显示,Chameleon不仅在图像生成、文本生成等单一模态任务上与Llama-2、Mixtral 8x7B、Gemini-Pro等模型相差无几。
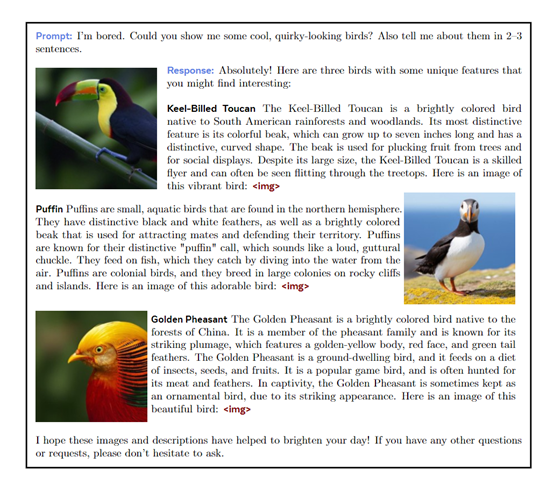
特别是可在长格式的混合模态生成任务中,根据人类评判,达到或超过Gemini Pro和GPT-4V等更大模型的性能。
申请模型地址:https://ai.meta.com/resources/models-and-libraries/chameleon-downloads/?gk_enable=chameleon_web_flow_is_live
本文素材来源Chameleon论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



