谷歌推出通用视频模型:能精准分类、定位、检索等
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
谷歌的研究人员推出了通用视频模型VideoPrism,可以用于视频领域的多种任务,例如,内容分类、定位、检索、字幕和回答等。
VideoPrism能拥有如此强的泛化能力,主要是使用了3600万段高质量的视频-字幕,以及5.82亿段带有噪声平行文本(如ASR文字转录、生成字幕等)的庞大预训练视频数据。
为了测试VideoPrism的通用性能,研究人员在33个视频理解基准测试集上,涵盖4大类任务通用视频理解、视频-文本检索、视频字幕生成和问答进行了综合测试。
结果显示,VideoPrism在30个基准测试上取得了最佳成绩,在通用视频分类和定位任务上,VideoPrism-g比目前最先进的视频模型VidepMAE-v2-g平均提升了22%的精准度。
论文地址:https://arxiv.org/abs/2402.13217
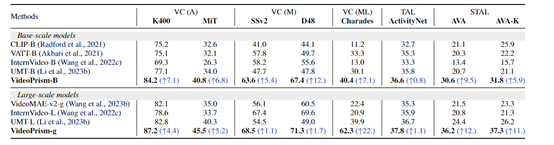
VideoPrism架构简单介绍
VideoPrism使用了卷积神经网络来对视频帧进行特征提取。这些卷积神经网络由多个卷积层和池化层组成,可以精准捕捉视频中的空间信息。再通过这些卷积操作,使每个视频帧都被转换为一个高维的特征向量。
VideoPrism还使用了Transformer架构中的自注意力机制,用于对视频中不同时间步的特征进行建模。自注意力机制能够学习到每个时间步之间的依赖关系,从而更好地捕捉视频中的时序信息,帮助VideoPrism对视频中不同时间步的特征进行加权组合,得到更具表征性的视频表示。

除了卷积和自注意力,VideoPrism还采用了残差连接来促进信息的流动。残差连接可以将原始的视频特征与经过卷积和自注意力处理后的特征进行相加,从而保留了原始特征的信息,并且能够有效地缓解梯度消失问题。
此外,VideoPrism还应用了层归一化(Layer Normalization)来提高模型的训练稳定性。层归一化可以对每个特征维度进行归一化,使得不同特征之间的关系更加一致。这有助于加速模型的收敛速度,并提高模型对不同类型视频的泛化能力。
预训练策略
VideoPrism预的训练过程主要包括两大阶段:第一阶段是视频-文本对比训练,使用对比损失函数对视频编码器和文本编码器进行联合训练,从而学习语义视频嵌入表示。这为第二阶段的掩码视频建模打下基础。
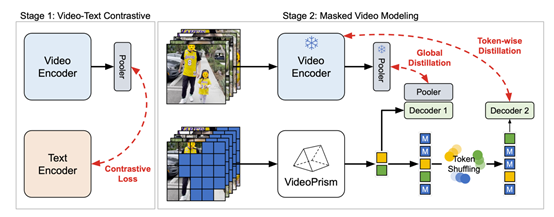
第二阶段,仅靠第一阶段的表示特征,模型还无法充分学习视频中的各种动态信息。因此,研究人员在视频数据上进行掩码视频建模以捕捉更多运动信息,同时使用了两种优化方法进行了性能优化。
随机Token混洗,将编码器输出的Token序列随机打乱,再输入解码器中,来阻止解码器直接复制未遮掩的Token;
全局-局部知识蒸馏,让第二阶段的学生模型不仅预测遮掩Token,还要在未遮掩Token上回归第一阶段老师模型的全局视频嵌入和Token-wise嵌入,从而完整的保留表示特征。
研究人员表示,VideoPrism作为一款通用视频模型其场景化落地非常广泛,例如,在视频理解和分析、智能视频监控、视频检索和推荐、专业科学视频分析等领域拥有广阔的应用空间,可以根据特定的条件进行精准数据分析、归类、定位等操作。
本文素材来源VideoPrism论文,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



