斯坦福、丰田最新研究,单视频合成多视角模型GCD
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
在AI视觉领域精准地从单一视角,重建复杂动态场景是一个非常难的课题。尽管OpenAI的Sora可以长达一分钟的高质量视频,但在没有多视角视频输入的情况下,实现动态新视角视频的合成能力仍然不足。
因此,斯坦福大学、丰田和哥伦比亚大学的研究人员联合推出了创新模型GCD,可以在仅提供一段任意场景的视频基础上,能够根据一组相对相机位姿参数,同步生成从其他任意360度视角的视频。
GCD的技术创新在于,不依赖深度数据作为输入,也不直接建模三维场景几何框架,而是通过端到端、视频到视频的方法来直接完成生成,帮助开发者探索动态场景的视觉理解和模拟。
例如,在自动驾驶测试中,GCD可以用来生成不同视角的驾驶场景,用于自动驾驶车辆的训练,帮助AI更好地理解和应对各种道路情况。
论文地址:https://gcd.cs.columbia.edu/GCD_v3.pdf
GCD架构简单介绍
GCD的视频生成模型是在Stable Video Diffusion(简称“SVD”)模型基础之上进行了修改和优化,使其能够接受相机姿态参数作为输入,从而控制生成视频中的相机多视角。
同时内置了“微条件机制”模块,帮助模型可以接受期望帧率、光流量等低维元数据,并通过多层感知处理这些信息,将它们嵌入到网络的不同卷积层中,这样模型就能在生成视频时考虑到相机的旋转和平移,实现多视角的精确控制。

为了确保生成的视频能够准确反映输入视频中的动态场景,GCD的视频生成模型还采用了混合条件机制,主要有两个流程:1)利用CLIP模型计算输入视频帧的特征嵌入,并通过交叉注意力机制对U-Net进行条件化;
2)将VAE编码的输入视频帧与正在去噪的视频样本帧,进行通道级联。
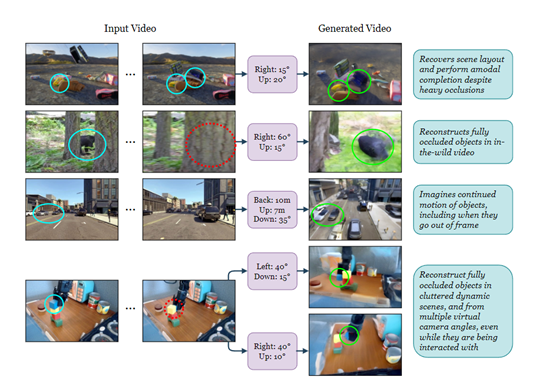
这种混合条件机制使得模型在生成视频时,能够同时考虑到输入视频的视觉信号和动态信息,分析输入视频中可见的形状和外观,并根据世界知识和观察到的其他帧推断出被遮挡区域,增强对复杂动态场景的完整重建。
训练数据集
研究人员在训练GCD时,使用了两个高质量的合成训练数据集Kubric-4D和ParallelDomain-4D。
这两个数据集专为动态场景视图合成任务而构建,提供了丰富的多视角视频片段,覆盖了多样化的动态场景,例如,机器人操作、驾驶环境和具有重度遮挡的自然场景,为AI模型学习如何在动态环境中处理视角变换和遮挡问题提供了重要基础。
Kubric-4D数据集是一个通用的多物体交互视频数据集,它具有高度的视觉细节和物理真实感。这个数据集的特点是场景中包含的物体数量多,物体之间的交互复杂,且常常出现复杂的遮挡模式。

在Kubric-4D中,每个场景包含7到22个随机大小的物体,其中大约三分之一的物体在视频开始时被放置在半空中,以增加动态效果。这些场景以24帧每秒的速率生成,每个场景包含60帧,从16个虚拟相机的固定姿势渲染RGB-D数据。
为了增强数据的多样性,研究者们采用了一种数据增强技术,将所有可用视点的像素合并到每个帧的3D点云中,然后根据可控制的相机轨迹重新渲染视频。
ParallelDomain-4D数据集则是专为驾驶场景设计的,提供了复杂、高度逼真的道路场景视频。这个数据集覆盖了各种地点、车辆、行人、交通情况和天气条件,为模型提供了丰富的环境理解和空间推理技能的训练材料。

ParallelDomain-4D中的每个场景包含50帧,以10帧每秒的速率生成,提供了包括RGB颜色、语义类别、实例ID等多模态的高质量注释,以及从19个虚拟相机的固定姿势渲染的逐像素真实深度。这些注释为模型提供了额外的上下文信息,有助于模型对场景理解和视频生成质量。
本文素材来源GCD论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



