谷歌推出全新模型,将Transformer与NAR相结合
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
Transformer架构的出现极大推动了大模型的技术创新,诞生出了ChatGPT、Coplit、讯飞星火、文心一言等一系列生成式AI产品。
虽然Transformer在自然语言理解任务上表现很好,但在算法推理方面有严重的缺陷。例如,当面临超出训练数据分布的输入时,其泛化能力会急剧下降。这主要是因为它们的自回归性质和掩蔽注意力机制,不符合算法输出的逻辑顺序。
而神经算法推理(NAR) 在结构化输入上表现好,能够处理各种算法任务,并且在面对训练集之外的更大输入时仍能保持完美的泛化能力。因此,谷歌DeepMind的研究人员将Transformer与NAR相结合推出了——TransNAR。

NAR是一种专门处理图结构数据的神经网络,其算法的计算步骤被表示为图的节点和边,而节点之间的信息通过边进行传递和更新。这种巧妙设计使得NAR能够自然地表达算法的逻辑流程,包括条件判断、循环迭代等编程结构。
在TransNAR架构中,研究人员并没有简单地将Transformer和NAR串联或并联,而是通过一种称为跨注意力的机制进行深度融合。
在这种机制下,Transformer的每一层都能够接收来自NAR的节点和边的嵌入信息,这些信息通过查询、键和值的形式进行交互,从而实现信息的流动和整合。
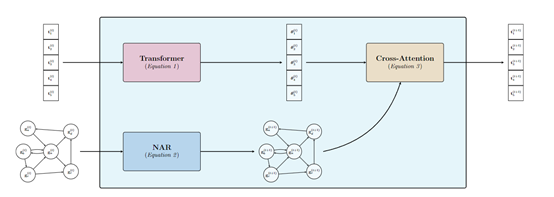
TransNAR的输入主要包括文本形式的算法问题描述,以及相应的图表示两大块:首先文本输入被送入Transformer层,通过标准的Transformer操作,如自注意力和前馈网络,来生成文本的表示。
同时,图表示被送入NAR层,通过图神经网络的操作,如最大池化或消息传递,来生成图的节点和边的表示。
当Transformer和NAR各自准备好了自己的表示后,跨注意力机制开始发挥作用。Transformer的查询与NAR的键进行匹配,通过softmax函数进行归一化,然后与NAR的值进行加权求和,最终生成Transformer的输出。这一过程在模型的每一层都会重复迭代,直到最终生成模型的输出。
多层级训练策略也是TransNAR成功的关键之一。在预训练阶段,NAR被独立训练,以执行CLRS-30中的算法。CLRS-30是一个包含多种算法任务的基准,这些算法任务被转换为图表示形式,以便NAR能够处理。
通过这种方式,帮助NAR能够学习到各种算法的内在逻辑和计算步骤,在面对不同算法任务时,能够展现出强大的鲁棒性和泛化能力。
在微调阶段,TransNAR开始接受包含文本描述和图表示的双重输入。此时,Transformer部分开始发挥作用,利用预训练的NAR提供的节点嵌入信息,通过跨注意力机制来调节自身的标记嵌入。
此外,在微调的时候Transformer的参数是可训练的,而NAR的参数保持冻结。这将帮助Transformer在保持NAR鲁棒性的同时,学习如何将自然语言描述转换为算法步骤,以确保模型能够稳定地学习和收敛。

研究人员通过CLRS-Text基准测试,对TransNAR综合测试。结果显示, TransNAR模型在多种算法任务上显著优于基线Transformer。
尤其是在分布外的泛化能力上,TransNAR展现出了超过20%的优化改进。这表明TransNAR能够有效地处理训练数据之外的更大或更复杂的问题实例。
本文素材来源TransNAR论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



