Meta开源多token预测,提升大模型推理效率
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
在今年5月27日,「AIGC开放社区」曾为大家解读了一篇名为《Meta等最新研究:多token预测,提升大模型推理效率》的论文。
7月5日,Meta开源了该创新框架,希望提升大模型推理效率并节省资源的小伙伴们可以试试这个。
开源地址:https://huggingface.co/facebook/multi-token-prediction

GPT-4、Llama-3等开闭源大模型,通常使用的是下一个token预测的损失函数进行预训练。这种方法虽然强大,但有很多局限性,例如,需要大量的训练数据才能使模型达到人类儿童的智商,并且随着模型参数的增大推理效率会变差。
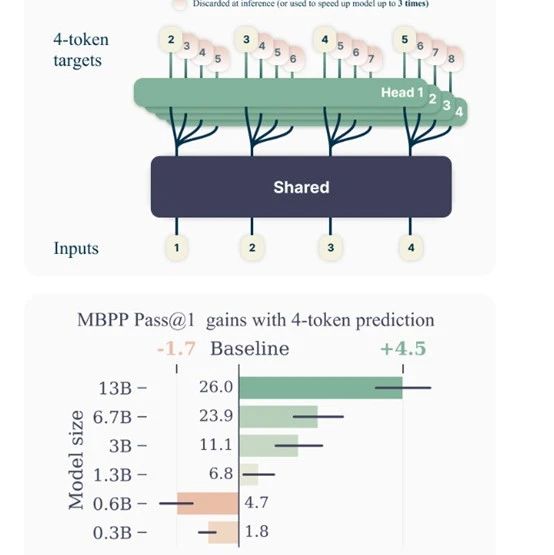
所以,Meta等研究人员提出了全新训练方法“多token预测”(Multi-token Prediction),在训练的过程中要求模型在每个位置上同时预测接下来的n个Token,以提升模型推理效率,并且不会增加预训练时间。
多token预测包含一个共享的Transformer主干网络,用于从输入获取上下文表示。然后该上下文表示被并行输入到n个独立的输出头网络中,每个输出头负责预测一个未来Token。
在推理阶段,只需使用单个下一Token预测,输出头即可进行自回归生成。而其他输出头则可被用于加速模型的推理效率。
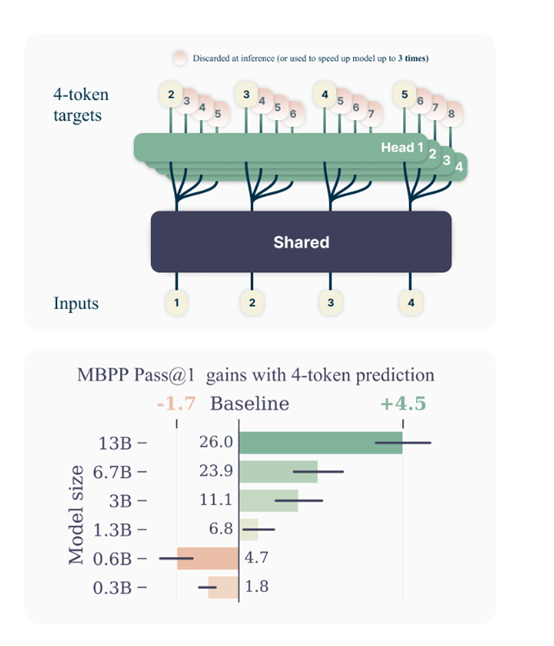
对于训练语料中的每个位置,模型需要使用独立的输出头预测接下来的n个Token。将多Token预测作为辅助训练任务,可以提高模型在代码和自然语言文本方面的任务性能,而不会增加训练时间。
为了解决多token预测可能导致GPU内存使用量增加的问题,研究人员开发了一种前向和后向传播顺序,模型能够减少在内存中同时存储的梯度数量,从而降低了内存使用量使得训练更加高效。
在前向传播过程中,模型会首先通过共享主干生成潜在表示,然后按顺序计算每个独立输出头的前向传播。
对于每个输出头,计算完毕后立即进行后向传播,并释放该头的中间数据,而不是等到所有输出头的前向传播完成后才进行。
在每个输出头的后向传播中,累积梯度到共享主干,而不是在所有输出头计算完毕后才进行。这样可以确保在任何时候,内存中只存在一个输出头的梯度。
研究人员在130亿、67亿、30亿等多种不同参数的模型对该技术进行了综合评估。结果显示,130亿参数模型在 HumanEval上解决问题能力提高了12%,在 MBPP上解决能力提高了17%。
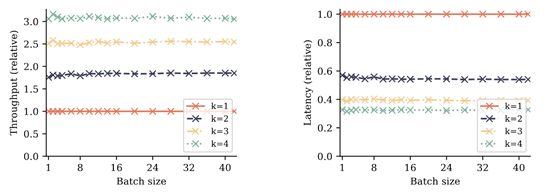
此外,多token预测在推理效率上也表现出色,尤其是对于大规模批处理。评测数据显示,经过4 token训练的模型在推理时速度可提升3倍。
本文素材来源多token预测论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



