苹果开源视觉模型界的“瑞士军刀”,能执行数十种任务
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
苹果和瑞士洛桑联邦理工学院的研究人员联合开源了大规模多模态视觉模型——4M-21。
多数大模型通常针对特定任务或数据类型进行优化,这种专业化虽然能确保在特定领域的高性能,但也限制了模型的通用性和灵活性。
例如,开源模型Stable Difusion只能用于文生图,即便是Gemini这种多模态模型,也只能生成和解读图片。
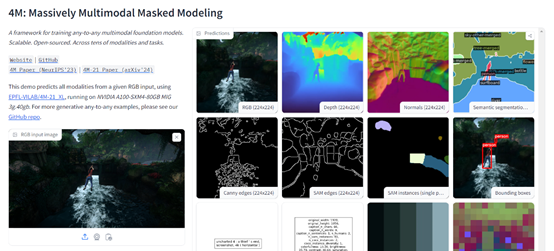
而4M-21只有30亿参数,却可以提供图像分类、目标检测、语义分割、实例分割、深度估计、表面法线估计等数十种功能,基本相当于视觉模型界的“瑞士军刀”功能很全面。
开源地址:https://github.com/apple/ml-4m/
论文地址:https://arxiv.org/abs/2406.09406
在线demo:https://huggingface.co/spaces/EPFL-VILAB/4M

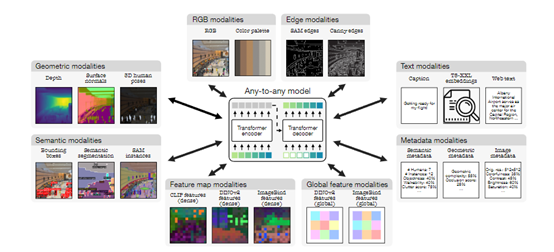
4M-21能提供如此多的功能,其关键核心技术是“离散tokens”转换技术。简单来说,就是将各种模态的数据转换为统一格式的tokens序列数据。
无论是图像类数据、神经网络特征图、向量、结构化数据(实例分割或人体姿态),还是以文本形式表示的数据,都可以转换成模型可以理解的同一数据格式。
这不仅简化了模型的训练,还将原本形态各异的数据被映射到一个共享的、易于处理的表示空间,为多模态学习和处理奠定了基础。
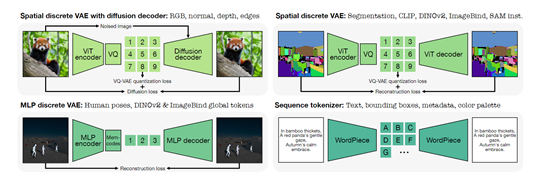
对于图像类数据,例如,边缘检测图或特征图,研究人员使用了基于Vision Transformer的变分量化自编码器进行标记化,生成一个固定大小的小网格tokens阵列。
对于那些需要高保真度重建的任务,例如,RGB图像,会采用扩散解码器来增强视觉细节的恢复。
而对于非空间模态,全局嵌入或参数化的人体姿态等,则利用Bottleneck MLP和Memcodes量化方法将其压缩成少量的离散tokens。
至于文本、边界框、颜色调色板或元数据等序列数据,则通过WordPiece分词器编码为文本tokens,利用共享的特殊tokens来标识它们的类型和值。
在训练阶段,4M-21通过掩码建模的方法来完成多模态学习,会随机遮盖输入序列中的部分tokens,然后基于剩余未遮盖的tokens预测被遮盖的部分。
这种方法迫使模型学习输入数据的统计结构和潜在关系,从而捕捉到不同模态间的信息共通性和交互性。
此外,掩码建模不仅提升了模型的泛化能力,还提升了生成任务的准确性,能够以迭代的方式预测缺失的tokens。

无论是通过自回归(逐个预测)还是逐步解码(逐步揭示遮盖部分)的方式。使得模型在解码过程中能够生成连贯的输出序列,包括生成文本、图像特征或其他模态的数据,从而支持多模态处理能力。
研究人员将4M-21在图像分类、目标检测、语义分割、实例分割、深度估计、表面法线估计以及3D人体姿态估计等测试平台中进行了综合评测。
结果显示,4M-21的多模态处理能力可以媲美当前最先进的模型。例如,在COCO数据集上,在语义和实例分割任务上表现出色,准确识别和区分图像中的多个对象;
在3DPW数据集上的3D人体姿态估计任务中也取得了显著的成绩,能够精确捕捉人体的姿态变化。
本文素材来源4M-21论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



