哈佛、麻省推出面向医学多模态助手—PathChat
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
哈佛医学院、麻省理工学院、俄亥俄州立大学韦克斯纳医学等研究人员联合推出了,面向医学领域的多模态AI助手——PathChat。
PathChat不仅能理解、分析复杂的医学图像,还能基于多轮文本对话,为临床医生、医护人员提供精准和个性化的病理学指导。
论文地址:https://www.nature.com/articles/s41586-024-07618-3
为了提升PathChat的多功能处理能力,使用了一个多模态架构由视觉编码器、多模态投影和大语言模型三大块组成。
视觉编码器充当PathChat的“眼睛”也是整个架构的核心模块之一,可将高分辨率的病理学图像转换成机器可以处理的低维特征表示,使得视觉信息能够被语言模型理解和处理。视觉编码器使了自监督学习方法,可以从未标记的图像中学习。
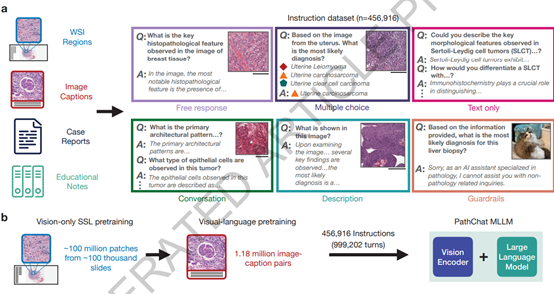
多模态投影模块作为视觉与语言的桥梁,接收了图像特征的进一步处理。该模块通过注意力池化层和多层感知器(MLP)来实现,将视觉特征图转换为固定长度的图像标记序列。这些图像标记随后被映射到与语言模型的嵌入维度相同的空间,为后续的语言模型处理做好了准备。
大语言模型方面,PathChat使用的是Meta开源的Llama 2家族的130亿参数变体作为其核心模型。
这是一个基于Transformer架构的自回归语言模型,包含40层Transformer,每层有40个注意力头,嵌入维度为5,120,隐藏维度为13,824,并采用了旋转位置编码,能够处理长达4,096的上下文序列。不仅能够处理文本,还能在接收到视觉特征后,给出准确的文本回应。

PathChat的训练过程分为两个阶段。在预训练阶段,大语言模型的权重被冻结,只有多模态投影模块接收参数更新。
该阶段的目的是让投影模块学会如何将视觉编码器的输出即图像的低维特征表示——映射到与大语言模型的文本嵌入空间相同的维度,使用了大约100,000对图像和字幕对。
随后,进入PathChat指令微调阶段,大语言模型和投影模块共同接受端到端的训练,以生成对多样化指令的响应。
这些指令包括了自然语言和视觉输入,反映了病理学领域内的真实查询。通过这种方式,PathChat能够学习如何理解和生成与病理学相关的复杂响应。
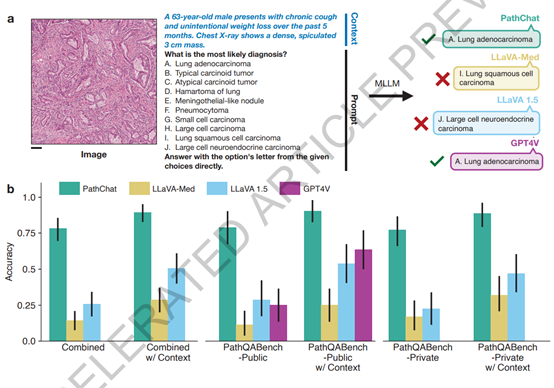
为了验证其性能,PathChat在多项选择诊断问题和开放性问答场景中接受了测试。结果显示,在面对公开和私有病例的诊断测试时,PathChat相比LLaVa-1.5、GPT-4V等模型具有显著优势,尤其在综合考量了图像和临床情境的诊断问题上,其准确率超出20%以上。
除了在测试中的优异表现,PathChat还展现了其在多种应用场景中的潜力。例如,它能分析不同器官部位的病理图像,参与人机交互的鉴别诊断过程,尤其在资源有限或处理如未知原发性癌症等复杂情况时,PathChat通过与病人的多轮深度对话,逐步缩小鉴别范围,辅助医生作出更精确的诊断。
本文素材来源PathChat草稿论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



