IBM推出创新框架用“黑盒”方式,评估大模型的输出
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
相比性能、评测排名,大模型输出的内容准确性、安全性和可解释性更加重要,无法做到这些商业化落地也就无从谈起。
IBM的研究人员开发一种框架通过黑盒的方式,无需访问大模型的内部结构、参数或训练数据,就能评估大模型的输出、置信度等。
论文地址:https://arxiv.org/abs/2406.04370

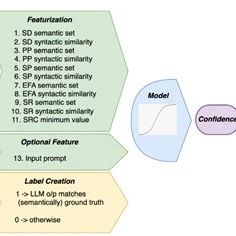
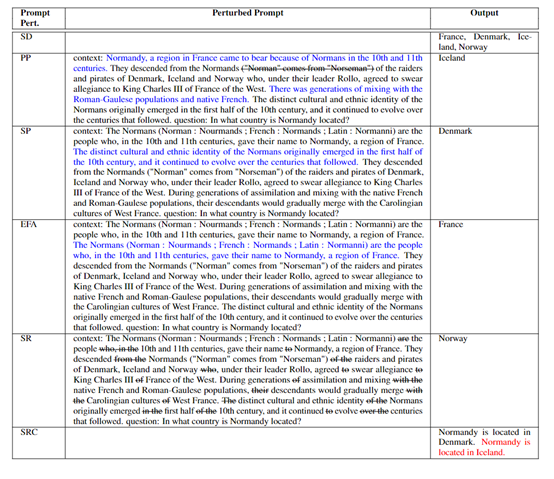
为了能激发出大模型在输出上的变异性,研究人员提出了六种不同的提示扰动策略:1)随机解码,它通过使用不同的解码技术,例如,贪婪搜索、束搜索和核心采样等,来生成多个输出,从而反映出模型对其响应的不确定性。
2)释义,通过将提示的上下文进行释义,比如使用反向翻译技术,将文本从一种语言翻译到另一种语言然后再翻译回来,以此来观察输出的变化。如果释义后的输出与原输出在语义上保持一致,这表明模型对其输出相当自信。
3)句子排列,通过改变输入中命名实体的顺序,来测试模型输出的一致性。如果模型对其输出非常有信心,那么即使实体顺序发生了变化,输出也应该保持不变。
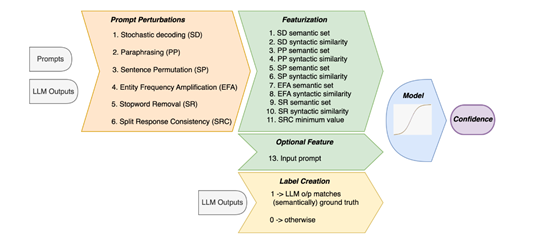
4)实体频率放大,通过重复包含命名实体的句子,来测试模型是否会因为信息的重复而改变其输出。
5)停用词移除,通过移除常见的停用词,来观察这些通常被认为信息量较少的词是否会对模型的响应产生影响。
6)分割响应一致性,通过将模型的输出随机分割成两部分,并用NLI模型来测量这两部分之间的语义一致性。
此外,基于这些策略,研究人员构建了语义和句法两种特征,用于训练置信度模型。语义特征主要关注输出的语义等价集合的数量,如果一个大模型的输出能够形成多个语义等价集合,意味着模型对其输出不够自信。
句法特征则通过计算输出之间的句法相似性来评估置信度,相似度越高,模型对其输出的置信度也就越高。
在模型训练过程中,研究人员通过将特征与标签(基于输出与标准答案的匹配程度生成)配对,利用标准的监督学习流程来调整模型参数。
标签的创建基于一种简洁的规则:如果模型输出与真实答案的ROUGE分数超过一定阈值(例如,0.3),则认为模型对该问题的回答是正确的(标签为1);
否则视为错误(标签为0)。这种方法非常简单、高效,能有效区分出模型在不同问题上的表现差异。
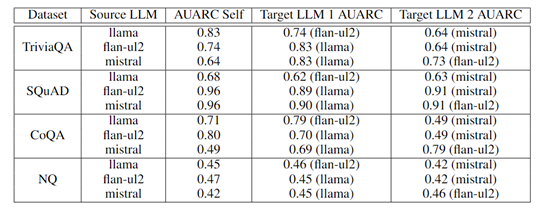
为了评估该框架的性能,研究人员在TriviaQA、SQuAD、CoQA和Natural Questions数据集上,通过在Flan-ul2、Llama-13b和Mistral-7b三款知名开源大模型上进行了实验。
结果显示,其框架不仅在多个数据集上显著优于现有黑盒的置信度估计方法,在AUROC指标上的提升超过了10%的性能。
研究人员表示,该框架的扩展性和应用性很强,可以随时向里面添加不同的扰动策略,来检测、适应不同类型的大模型。同时只需要在一个大模型上进行置信度模型训练,多数情况下可以应用到同类模型中。
本文素材来源IBM论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



