谷歌、Anthropic推出创新神经压缩Equal-Info Windows
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
谷歌DeepMind和著名大模型平台Anthropic的研究人员联合推出了创新神经压缩方法——Equal-Info Windows。
研究人员表示,随着ChatGPT、Gemini、Claude等大语言模型的参数、功能越来越复杂,其训练成本呈指数级上升。如果能用神经压缩的文本数据来训练模型,在训练和推理效率上带来质的提升,同时也能更容易处理超长文本。
但直接使用神经压缩数据,往往会生成不透明、不稳定的内容输出。例如,通过算术编码进行简单的文本压缩,并不能使大语言模型学习到有效的训练知识。
而Equal-Info Windows将文本分割成多个窗口,每个窗口都压缩到固定长度的比特流,每个窗口的信息量大致相等。这种创新方法能够提供一种稳定的映射关系,使得压缩后的文本数据更容易被大语言模型学习。
论文地址:https://arxiv.org/abs/2404.03626

窗口分割
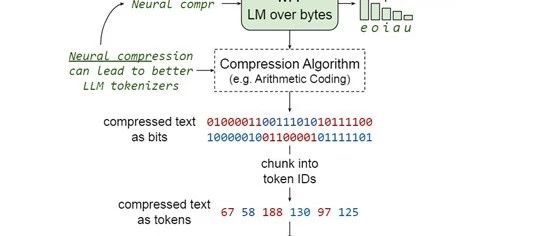
首先,Equal-Info Windows通过“窗口分割”的方法将原始文本数据分割成一系列的连续字符序列,每个序列被视为一个独立的窗口。
窗口的大小可以根据特定的需求进行随意调整,但通常是一个固定的长度,方便于后续的数据压缩。
在Transformer架构的大语言模型中,自注意力机制需要在整个序列上计算,在长文本上是非常消耗时间和算力。
这种窗口分割方法有助于减少大语言模型在处理长距离依赖时的计算负担,使模型可以专注于局部上下文从而提高处理速度和效率。
窗口压缩
在获得窗口分割数据后,通过“窗口压缩”方法将每个分割后的窗口独立压缩到一个固定长度的比特串。这可以在在保持原始文本信息的同时,尽可能减少所需的存储空间和AI算力资源。
每个文本窗口首先被转换为一个数值序列,通常将字符映射到它们在字符集中的角色标识符。接着,这些数值序列被送入到算术编码(AC)进行压缩。通常这些算法通过学习文本中的符号频率和模式来优化压缩过程,从而实现高效的比特级压缩。

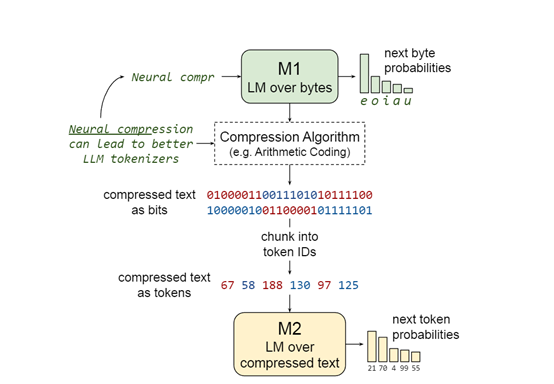
在压缩的过程中,研究人员训练了M1和M2两个模型。M1的主要作用是,将原始文本数据转换为压缩后的比特流。这一步骤是实现神经网络压缩的关键环节,使得后续的模型预训练能够在更紧凑的数据表示上进行。
M2模型则是学习如何从压缩的比特流中恢复和理解原始文本的信息。包括学习如何处理和解码由M1模型生成的压缩数据。
同时在推理阶段,M2模型能够基于压缩输入生成未压缩的文本输出。这意味着M2不仅能理解压缩文本,还要能逆转压缩过程,还原出原始文本或生成新的文本序列。
实验数据
为了评测该方法的性能,研究人员对比了Equal-Info Windows压缩的文本和传统子词分割器(如SentencePiece)处理的文本。
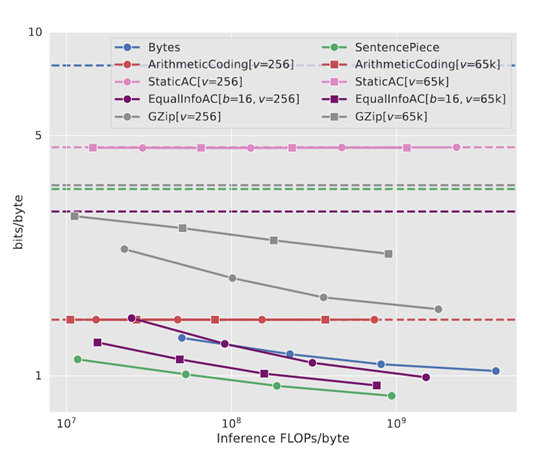
结果显示,尽管Equal-Info Windows在模型参数数量相同的情况下,其困惑度略高于子词分割器,但在减少序列长度方面有明显的优势。这说明Equal-Info Windows能够在较少的自回归步骤中生成文本,从而降低了模型推理时的延迟。
此外,研究团队还发现,Equal-Info Windows在处理长文本时表现非常出色。由于每个压缩窗口都包含大致相等的信息量,大语言模型能够更好地捕捉文本中的长距离依赖关系。这一点在处理文档检索和编码问题等任务时尤为重要。
本文素材来源Equal-Info Windows论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



