谷歌开源Gemma-2:参数小,同类性能最佳之一
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
6月28日,谷歌在官网宣布开源最新大模型Gemma 2,专门面向研究和开发人员。
据悉,Gemma 2一共有9B和27B两种参数(还有一个2.6B没介绍),与上一代相比性能大幅度提升,但部署要求却大幅度下降只需要一块NVIDIA H100 Tensor Core GPU或TPU主机就能使用。
在同类小参数模型中,Gemma 2超过了Llama-3 8B、等知名模型,性能逼近Qwen1.5成为同类最佳模型之一。
开源地址:https://www.kaggle.com/models/google/gemma-2
在线使用:https://aistudio.google.com/app/prompts/new_chat?model=gemma-2-27b-it

Gemma 2的架构在上一代的基础之上进行了全方位改良,使用了局部滑动窗口注意力和全局注意力,其中局部注意力层的滑动窗口大小设置为4096个tokens,全局注意力层的跨度设置为8192个tokens。
训练数据方面,Gemma 2的27B模型使用了13万亿tokens的英文数据进行训练,9B模型使用了8万亿tokens数据。这些数据包括网页文档、代码、论文和科学文章等。

训练策略方面,Gemma 2使用了知识蒸馏的方法,通过学习大型教师模型给出的输出概率进行训练。这种策略能够让学生模型模仿教师模型的行为,从而在较小的规模上复制大模型的卓越性能。
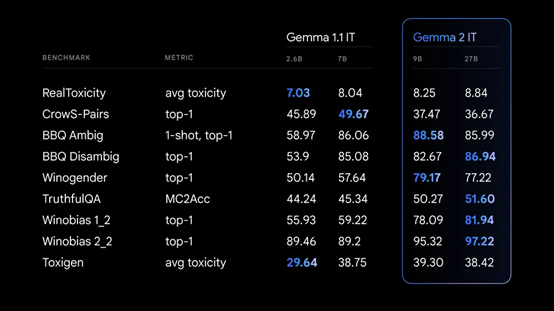
预训练阶段,Gemma 2在文本合成、英语合成和人类生成的提示-响应对上应用了监督式微调,然后在这个基础上应用了基于标记的英语偏好数据训练的奖励模型和基于相同提示的RLHF进行强化训练。
研究人员在MBPP、MMLU、ARC-C、GSM8K、BBQ Disambig等知名基准测试平台进行了综合评测。
结果显示,Gemma 2在多项基准测试中都表现非常出色,例如在MMLU 5-shot、ARC-C 25-shot、GSM8K 5-shot等测试中,27B模型相比之前版本和其他标准模型,如Mistral和LLaMA-3,均有明显提高。
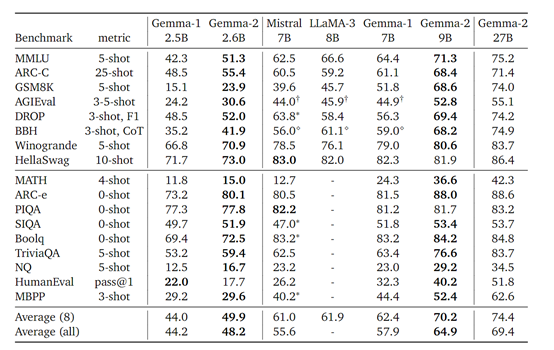
在MMLU 5-shot测试中, 27B的得分达到了75.2%,相较于Gemma-1的42.3%有显著增长。
在其他数学推理、逻辑问题解决和常识问答等任务上,Gemma 2同样显示出其在处理复杂认知任务上的强大效能。
本文素材来源Gemma 2技术报告,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



