谷歌推出创新方法:通过自然文本提示,快速训练视觉模型
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
目前,计算机视觉的应用已经渗透到了多个行业,从内容审核、交通安检到野生动物保护等。但主视觉是集中在狗、猫、汽车等客观分类上,对于情绪预测、美学评估等人性化内容较难,需要人工来进行数据标注。
如果使用最近推出的“敏捷建模”来训练一个微小视觉模型,最少需要人工对2000张图像进行数据标注,整个流程大概耗费30分钟且无聊枯燥。
谷歌和密苏里大学的研究人员推出了一种高效的视觉模型训练方法——Modeling Collaborator。
同样是上面那个2000张图像数据标注,通过Modeling Collaborator,人工只需要标准100张图像就能完成视觉模型的训练。
论文地址:https://arxiv.org/abs/2403.02626

Modeling Collaborator借助了人类对复杂概念的判断能力,例如,一位美食家评选上等烤牛排,会从食材、口感、色泽、火候、烹饪手法等多个维度去评价。
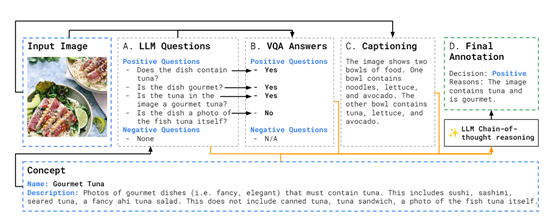
Modeling Collaborator主要包含大语言模型、图像描述生成模型和视觉问答模型,三种模型协同合作完成数据标注。
当用户输入一个概念名称和描述后,大语言模型会基于描述生成相关的原子问题,并将其提交给视觉问答模型获取答案。
再结合视觉问答模型的答复和图像描述生成模型的图像描述,通过思维链推理对输入图像进行标注。最后,用知识蒸馏的方式在大规模训练数据集上应用该方法,实现批量数据标准。
数据挖掘
传统的视觉模型开发需要人工定义概念,查找相关图像,并手动对图像进行标注,这是一个费力且容易出错的过程。Modeling Collaborator则通过利用大语言模型的推理能力来自动化这一过程。
当用户输入视觉物品的名称、描述(可以不填)后,大语言模型会基于这些信息生成多个正负样本查询。
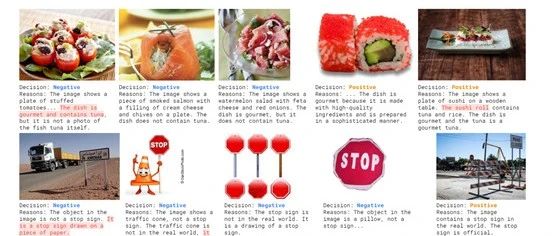
例如,对于”美味金枪鱼”这一概念, 大语言模型可能会生成”包含金枪鱼的菜肴”、”金枪鱼刺身”等正样本查询,以及”金枪鱼三明治”、”罐头金枪鱼”等负样本查询。
为了增加查询的多样性和覆盖面,大语言模型还会对初始查询进行变体扩展。它可能会生成该概念的更广义或更狭义版本,或是改变查询中的特定部分。每个查询都会被用于从公共数据集(如LAION)中提取潜在的图像样本。

这种基于大语言模型的数据挖掘方法可以克服人工标注中存在的偏差,并以更高的效率挖掘出更全面的正负样本。
虽然大语言模型可能也带有一些偏差,但它能从庞大的知识库去评估概念,比人工标注更有优势。
训练管道和主动学习
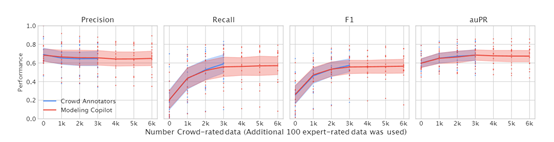
获得大量带标注的图像数据后,Modeling Collaborator会进入模型训练的阶段,这里采用的是与敏捷建模类似的方法。
首先,使用基于CLIP或ALIGN等视觉语义模型提取的图像特征作为输入,训练一个浅层的多层感知机模型进行二分类。可视为一种学生-教师蒸馏过程,其中大语言模型的注释模块扮演教师模型的角色。
然后通过主动学习阶段,进一步优化模型并弥补错漏。每一轮主动学习都包含三个步骤:
1)将当前学生模型应用于大量无标注图像数据库(如LAION),采用分层采样策略,选取少量疑难样本。
2)大语言模型注释模块为这些样本进行自动标注。
3)利用新标注的数据对学生模型进行微调和持续训练。
主动学习主要是用来发现并补充之前遗漏或覆盖不足的视觉模式,例如,硬负样本和硬正样本,从而提高模型的精确度和召回率。
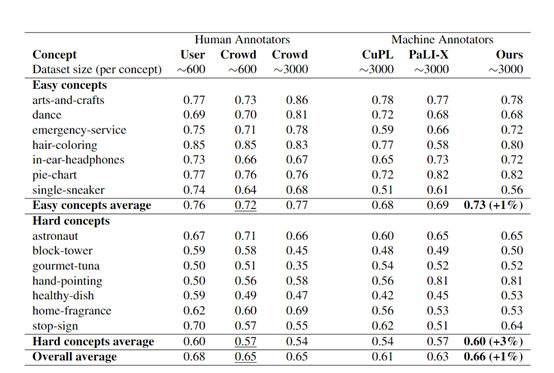
实验数据方面,研究人员在15个主观视觉概念和2个公开数据集上进行了综合测试。结果显示,通过Modeling Collaborator方法训练出的分类视觉模型的准确率超过了,现有的零样本分类和敏捷建模方法。
本文素材来源Modeling Collaborator论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



