麻省理工提出“跨层注意力”,极大优化Transformer缓存
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
Transformer在大模型领域的影响力不言而喻,ChatGPT、Sora、Midjourney、Suno、Llama、Stable Difusion等几乎所有知名开闭源模型,皆基于该架构开发而成。
但随着大模型参数呈指数级增长,小的几百亿大的上千亿甚至万亿,这使得Transformer在解码时所需的KV(键值)缓存急剧增加,会导致内存占用过大造成部署、推理方面的瓶颈。
所以,麻省理工的研究人员提出了全新的跨层注意力(Cross-Layer Attention, 简称“CLA”),通过在不同解码层间共享KV来显著降低对内存的使用,从而提升大模型在处理长序列和大批次推理任务时的效率以及准确率。
论文地址:https://arxiv.org/abs/2405.12981

目前,解决Transformer缓存瓶颈的方法是多查询注意力和分组查询注意力, CLA则是在这两者之上做了进一步优化。
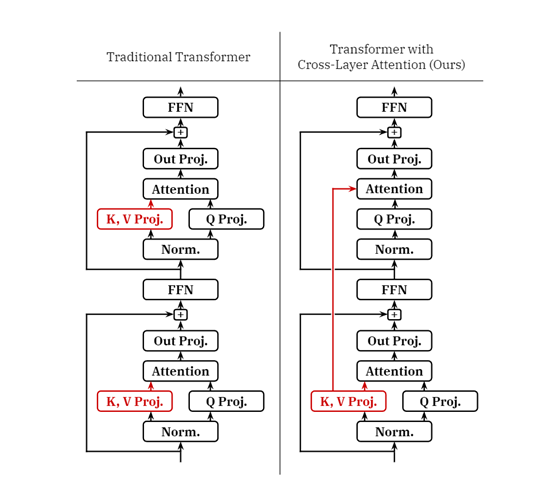
在传统的Transformer架构中,每一层都包含独立的KV投影,用于生成键值对;查询投影则负责生成查询向量;注意力模块可根据查询和KV对计算注意力分布;
输出投影进行整合注意力输出;残差连接和层归一化,主要用来确保学习稳定性和表现力。
CLA的核心思想是通过在相邻层之间共享KV来降低内存占用,而不是每层独立计算和存储。
在CLA中不同层之间的通信也是通过共享KV激活来完成的,这极大减少了模型必须维护的独立KV集合的数量,而其他层则通过层间连接重用这些激活。
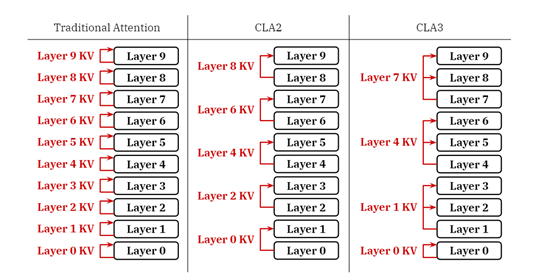
此外,CLA提供了灵活的配置允许开发者根据需要调整共享因子,以平衡内存使用和模型性能。共享因子定义了每个KV投影被多少层共享。例如,在CLA2配置中,每对相邻层共享一个KV缓存。
为了测试CLA的性能,研究人员在10亿和30亿参数上训练了多款CLA和非CLA模型,目的是在固定内存预算下找到CLA的最佳准确性。这些模型的变化涵盖了从MHA到GQA再到MQA的范围,KV缓存的内存需求也由此跨越了两个数量级。
为了确保结果的稳健性,研究人员对选定的几个模型进行了学习率调整实验,以确认CLA在与经过良好调整学习率的基线模型相比时是否具有优势。
实验结果显示,CLA在减少KV缓存大小的同时,能够实现与非CLA模型相当的推理准确性。在10亿参数规模的实验中,CLA模型成功地在保持准确度的基础上显著减少了KV缓存的大小。
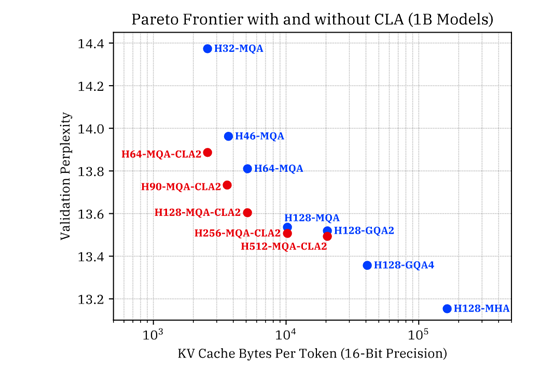
特别是MQA-CLA2配置在减少KV缓存大小方面表现非常出色,相比基线MQA模型,在相同的KV缓存内存下实现了更低的验证困惑度。
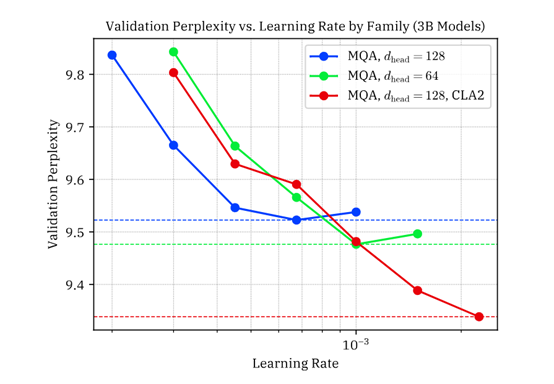
在30亿参数模型的实验中,CLA也展现了其高效性。CLA2配置在减少KV缓存大小的同时,与相同头维度的MQA基线模型相比,实现了更低的验证困惑度,进一步证明了CLA在大规模模型中的有效性。
本文素材来源CLA论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



