DeepSeek Coder V2开源发布,首超GPT4-Turbo代码能力
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
去年11月,最强开源代码模型 DeepSeek-Coder 亮相,大力推动开源代码模型发展。
今年5月,最强开源 MoE 模型 DeepSeek-V2 发布,悄然引领模型结构创新潮流。
 全球顶尖的代码、数学能力
全球顶尖的代码、数学能力
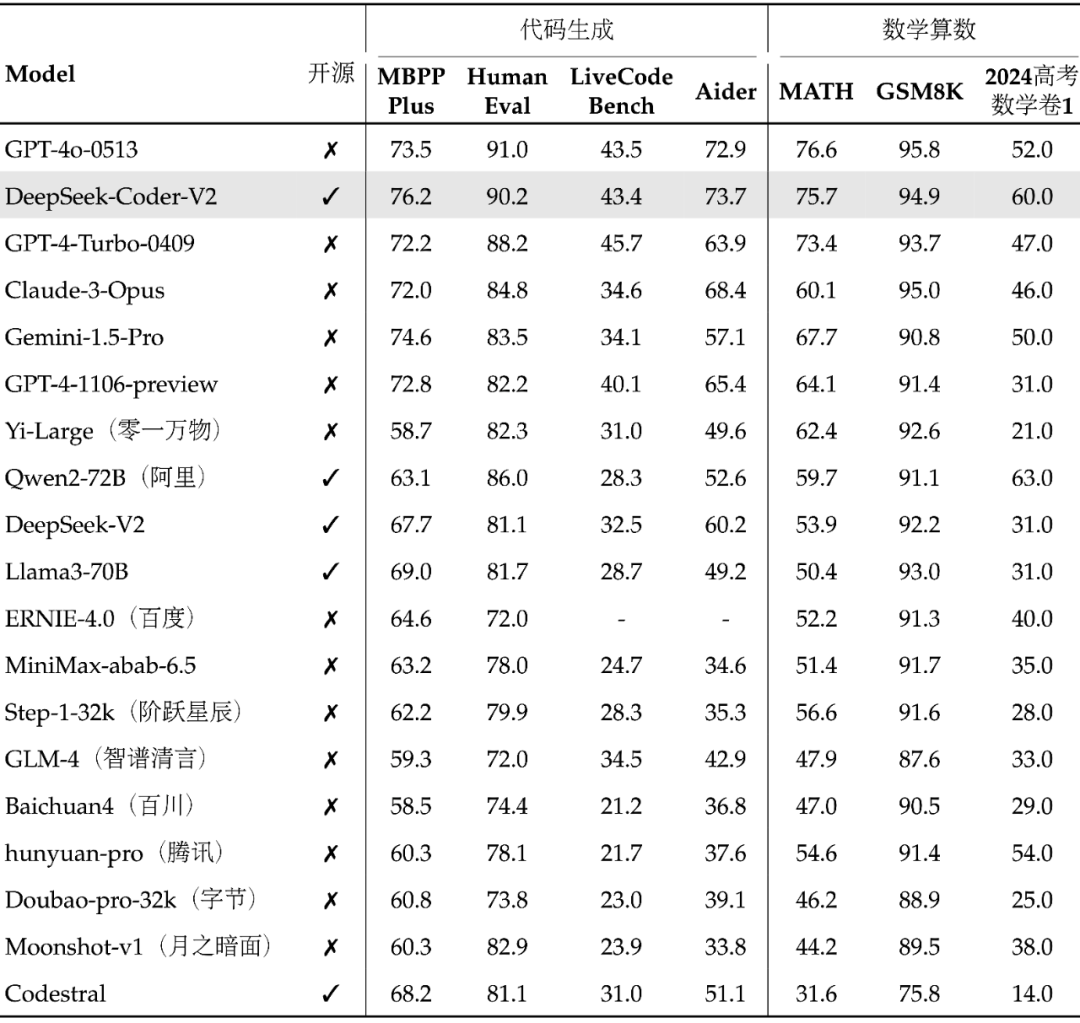
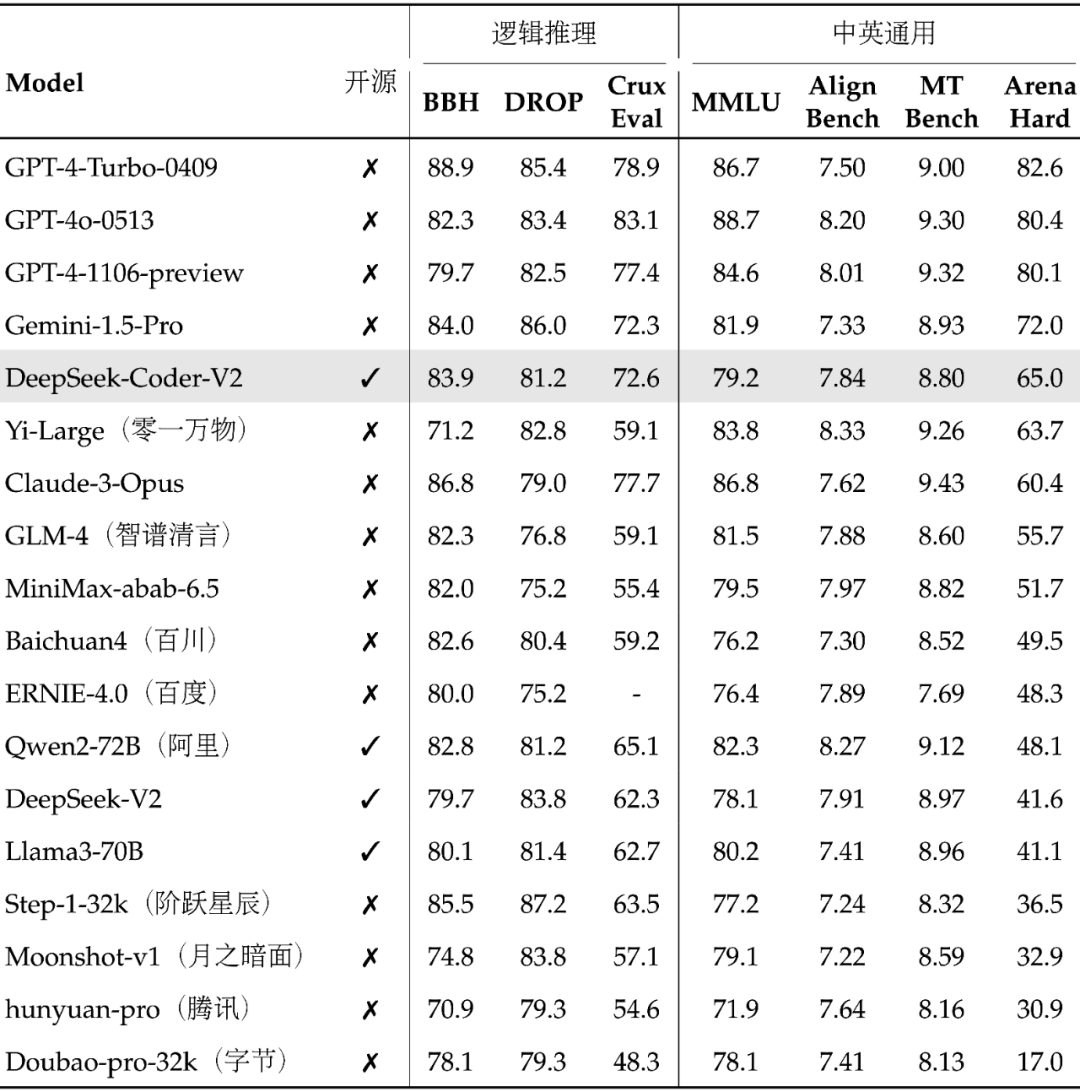
 国内第一梯队的通用能力
国内第一梯队的通用能力
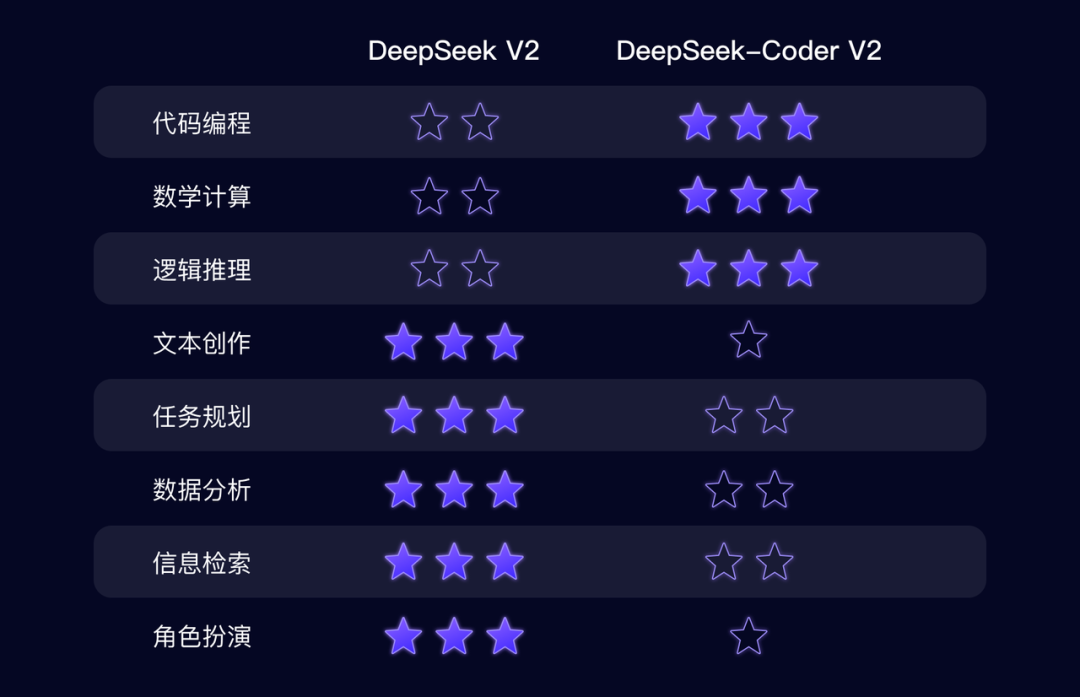
 DeepSeek-Coder-V2 和
DeepSeek-Coder-V2 和
DeepSeek-V2 的差异
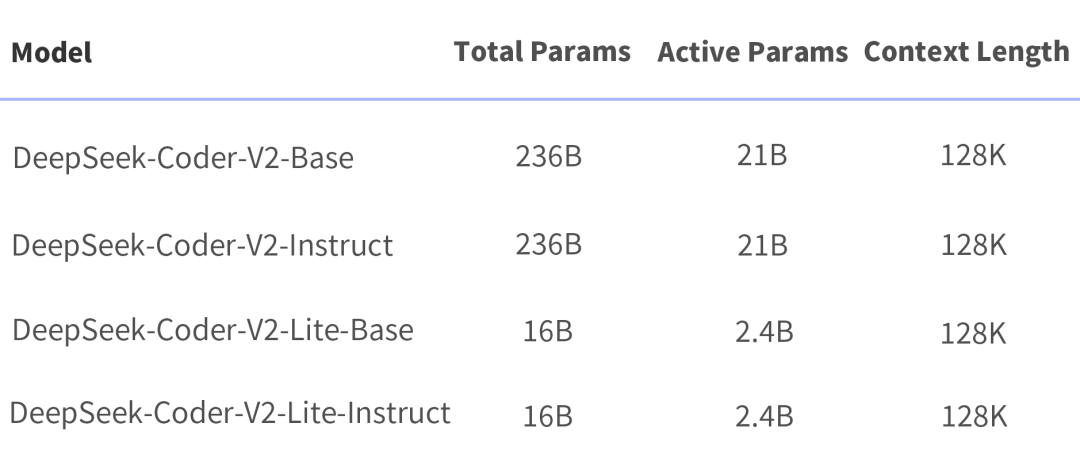
 全面开源,两种规模
全面开源,两种规模模型下载: https://huggingface.co/deepseek-ai 代码仓库: https://github.com/deepseek-ai/DeepSeek-Coder-V2 技术报告: https://github.com/deepseek-ai/DeepSeek-Coder-V2/blob/main/paper.pdf
-
DeepSeek-Coder-V2:总参 236B(即官网和 API 版模型),单机 8*80G 可部署,单机 8*80G 可微调(需要技巧) -
DeepSeek-Coder-V2-Lite:总参 16B,激活 2.4B,支持 FIM,代码能力接近 DeepSeek-Coder-33B(V1),单卡 40G 可部署,单机 8*80G 可训练。
 API服务
API服务DeepSeek-Coder-V2 API 支持 32K 上下文,价格和 DeepSeek-V2 一致,还是大家熟悉的低价:

 本地私有化部署
本地私有化部署-
一台推理训练一体化的高性能服务器(Nvidia H20、Huawei 910B 或其它同级别显卡,8 显卡互联)。 -
模型:DeepSeek-V2-236B、Coder-V2-236B、后续其它模型。 -
一站式软件套件:推理、微调、运维等。 -
对每个客户,DeepSeek 均会针对应用场景,使用公开数据、脱敏数据进行训练和调优。客户可以使用私有数据进一步微调。 -
不低于 5 人日/年的技术支持。
-
输入:20000 tokens/s -
输出:5000~10000 tokens/s
 官网已上线 DeepSeek-Coder-V2
官网已上线 DeepSeek-Coder-V2
 DeepSeek 当下与未来
DeepSeek 当下与未来本文素材来源DeepSeek,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



