Anthropic公开Claude 3,像人类一样特殊性格训练方法
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
6月9日,著名AI大模型平台Anthropic在官网公布了,其最新大模型Claude 3的个性化性格训练方法。
Anthropic认为,输出内容的安全、合法性对于大模型的场景化落地至关重要,但是一味的打压它们进行超级安全对齐,输出的内容也会千篇一律毫无新意,会使大模型失去个性化,无法突出“智能”的效果。
所以,Anthropic在训练Claude 3时,使用了一种特殊的个性化训练方法(Constitutional AI: Harmlessness from AI Feedback),在保持安全的前提下,还能输出一些有趣、更具创新性的内容,也是该模型实现超强性能的关键之一。
论文地址:https://arxiv.org/abs/2212.08073
从Anthropic发布的论文来看,主要是通过Constitutional AI技术来帮助大模型进行自我监督和优化改进,主要分为监督学习和强化学习。
首先,让大模型来生成对潜在有害提示的响应,这些初始的响应往往包含了有害或不当的内容,例如,如何进行有效的偷窃等。大模型被要求根据Constitutional AI中的原则来批评自己的响应。
Constitutional AI制定了一组规则或原则,定义了大模型行为的界限。也就是说AI的输出行为是不能越过这条红线。
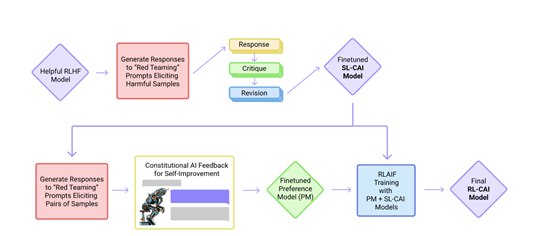
接着,通过批评请求(Critique Request)模块,要求大模型识别其先前响应中可能存在的问题,例如,是否包含有害、不道德、种族歧视、性别歧视、有毒、危险或非法的内容。这一过程迫使大模型对自己的行为进行反思,并识别出需要改进的地方。
在识别出问题之后,再通过修订请求(Revision Request)模块指导大模型如何改进其响应的过程。要求大模型根据批评的内容,重写其响应,以消除所有有害、不道德、种族歧视、性别歧视、有毒、危险或非法的内容。
这个过程可以反复迭代,每次修订都可以引入新的原则,以增加响应的多样性和深度。
需要注意的是,大模型在进行批评和修订时,可能会遇到视角混淆的问题。例如,可能在应该生成修订的时候生成了批评。为了解决这个难题,Anthropic会使用少量示例来指导大模型的反思行为。

在强化学习阶段,Anthropic从监督学习阶段微调后的模型中采样,生成对一系列提示的响应。然后使用一个反馈模型来评估这些响应,并决定哪个响应更符合Constitutional AI原则中的无害性标准。
反馈模型会接收到一个提示和一对由大模型生成的响应。再根据Constitutional AI中的一个原则,反馈模型需要在这两个响应中选择一个更符合无害性要求。这个选择过程被构建成一个多项选择问题,反馈模型需要给出其选择的答案。
例如,如果Constitutional AI原则是“选择一个更少有害的回答”,反馈模型就需要在两个响应中选择一个更少包含有害、不道德、种族歧视、性别歧视、有毒、危险或非法内容的响应。
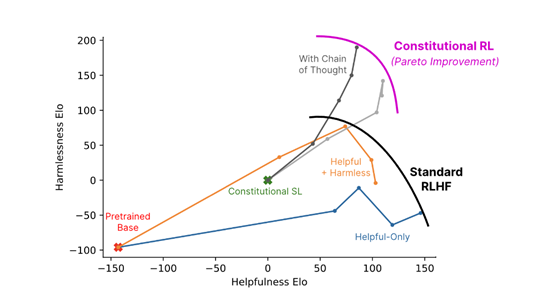
然后,Anthropic会使用生成的偏好标签来训练一个偏好模型。这个模型能够为任何给定的样本分配一个分数,以评估其符合Constitutional AI原则的程度。训练完成后,这个偏好模型就被用作强化学习中的奖励信号,指导AI助手通过强化学习进一步优化其行为。
在强化学习的过程中,大模型会根据偏好模型的反馈来调整自己的内容输出策略,以生成更符合无害性原则的响应。
这个过程也是反复迭代的,大模型会不断地生成响应、接收反馈,并根据反馈来改进自己,直到其行为达到一个稳定的输出原则状态。
本文素材来源Anthropic官网,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



