阿里开源Qwen 2,最强中文大模型之一!
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
6月7日,阿里巴巴正式开源了大模型——Qwen2。
Qwen2一共有5种预训练和指令微调模型, 包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B。
github地址:https://github.com/QwenLM/Qwen2
huggingface地址:https://huggingface.co/Qwen
在线demo:https://huggingface.co/spaces/Qwen/Qwen2-72B-Instruct
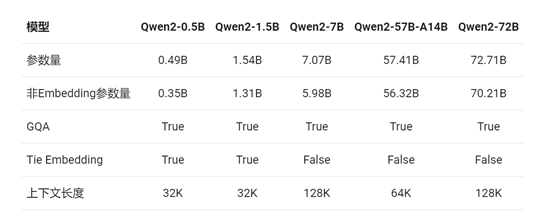
与相比Qwen1.5,Qwen2的性能实现大幅度提升。例如,本次发布的所有模型都使用了GQA,以便让大家体验到GQA带来的推理加速和显存占用降低的优势。
上下文长度方面,所有的预训练模型均在32K tokens的数据上进行训练,并且研究人员发现其在128K tokens时依然能在PPL评测中取得不错的表现。
但对指令微调模型而言,除PPL评测之外还需要进行大海捞针等长序列理解实验。在该表中,根据大海捞针实测结果,列出了各个指令微调模型所支持的最大上下文长度。而在使用YARN这类方法时,Qwen2-7B-Instruct和Qwen2-72B-Instruct均实现了长达128K tokens上下文长度的支持。
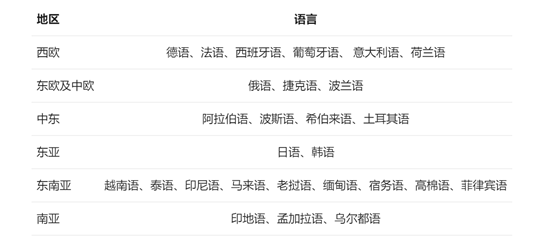
阿里表示,本次对Qwen2投入了大量精力研究如何扩展多语言预训练和指令微调数据的规模并提升其质量,从而提升模型的多语言能力。尽管大语言模型本身具有一定的泛化性,但还是针对性地对除中英文以外的27种语言进行了全面增强。
测试数据方面,在针对预训练语言模型的评估中,对比当前最优的开源模型,Qwen2-72B在包括自然语言理解、知识、代码、数学及多语言等多项能力上均显著超越当前领先的模型,例如,Llama-3-70B以及Qwen1.5最大的模型Qwen1.5-110B,主要益于预训练数据及训练方法的优化。

研究人员全面评估了Qwen2-72B-Instruct在16个基准测试中的表现。Qwen2-72B-Instruct在提升基础能力以及对齐人类价值观这两方面取得了较好的平衡。
相比Qwen1.5的72B模型,Qwen2-72B-Instruct在所有评测中均大幅超越,并且了取得了匹敌Llama-3-70B-Instruct的表现。
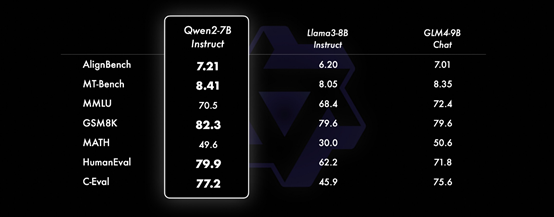
在小模型方面,Qwen2系列模型基本能够超越同等规模的最优开源模型甚至更大规模的模型。相比近期推出的最好的模型,Qwen2-7B-Instruct依然能在多个评测上取得显著的优势,尤其是代码及中文理解上,成为最强中文大模型之一。
本文素材来源Qwen2官网,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



