开源音频模型Stable Audio Open,文本生成47秒高清音效
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
6月6日,著名开源大模型平台Stability.ai在官网宣布,开源最新文生音频模型Stable Audio Open。
用户通过文本就能生成最多47秒,钢琴、笛子、鼓点、模拟人声等不同类型的44.1kHz音效。
值得一提的是,Stable Audio Open支持数据微调,歌手、音乐人可以让其生成基于自己的音乐数据,例如,架子鼓手可以根据自己的鼓点来进行微调。
开源地址:https://huggingface.co/stabilityai/stable-audio-open-1.0
在线demo:https://huggingface.co/spaces/artificialguybr/Stable-Audio-Open-Zero

根据Stability.ai介绍,Stable Audio Open使用了486,492个录音训练数据,其中 472,618 个来自Freesound,13874个来自免费音乐档案馆,并且所有音频文件均根据 CC0、CC BY或CC Sampling+获得了商业许可。
就是说通过Stable Audio Open生成的音效无需担心商业化问题,不会受到法律方面的追究。
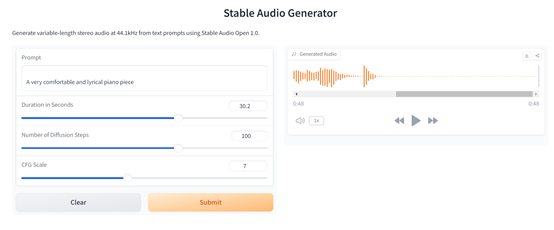
「AIGC开放社区」根据其提供的在线demo体验了一下,在文本语义理解、生成音效等方面还是相当优秀。
需要注意的是,目前只支持英文提示词,其他任何语言都不行,即便你使用了识别效果也是相当的差。
在生成的过程中,用户可以对时间、扩散步数和CFG进行详细控制,以达到更好的效果。例如,一首非常舒适抒情的钢琴曲。
真实的女声哼唱声音,轻松、惬意。
本文素材来源Stability.ai官网,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



